前回までで,データを読み込み,転記ミスなどの異常が無いかを確認しました。 また,適当回答や欠測値の処理を行い,ようやく分析ができる「きれいな」データを用意することが出来ました。 今回は本格的な分析に入る前の前段階として,項目や尺度の性質・性能を簡単に確認していきます。 この段階で,明らかに良くない項目は事前に削除しておくことによって,その先の分析でより安定した結果が得られるようになるはずです。
4.1 分布の可視化
データ内のゴミをある程度取り除けたところで,各変数の分布を見てみましょう。 量的変数の場合,要約統計量だけではなく分布を可視化するのも大事です。 心理尺度の場合,合計点だけでなく各項目のレベルで,できるだけ回答が正規分布に近い形でばらついている方が都合が良い事が多いです。 例えば「毎日睡眠をとっている」や「ここ1ヶ月人と会話していない」のように,ほぼすべての人に当てはまりすぎる・全く当てはまらないような項目は,ほぼすべての人が同じ回答になるため,その項目に対する回答が個人の特性値に対して何の情報も与えない可能性があります。 分析の前に,このような天井効果や床効果と呼ばれる状態が発生していないかを確認したり,分布のピークが一つになっているかを確認しておきましょう。 また余裕があれば,2変数の散布図を書いたりして,項目間の相関関係について想像したりするのも良いでしょう。
なお,ここから先では「とりあえず図を出す」レベルの話だけします。論文に載せるようなきれいなグラフを描きたい場合には色々引数をいじりまくる必要がありますが,それだけで1コマくらいは潰れると思うので…1
4.1.1 1変数の棒グラフ
リッカート尺度の項目反応など,取る値のパターンがせいぜい数個(離散変数や名義変数)の場合は,棒グラフが良いでしょう。棒グラフはbarplot()とtable()を組み合わせることで描けます。
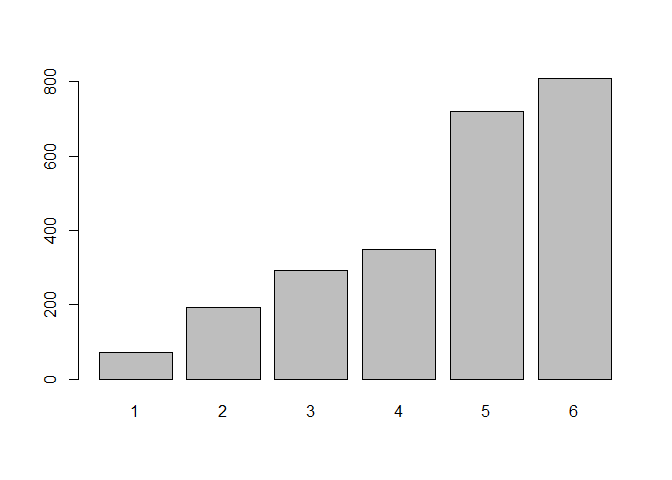
barplot()は,与えられたベクトルの一つ一つの値を棒の長さで表現する関数です。そのため,barplot(dat$Q1_1)というように直接データを与えてしまうと, 図 4.2 のように左から長さが2, 2, 5, 4, 2, …という感じで2800本の棒グラフが誕生してしまいます。

4.1.2 天井効果と床効果
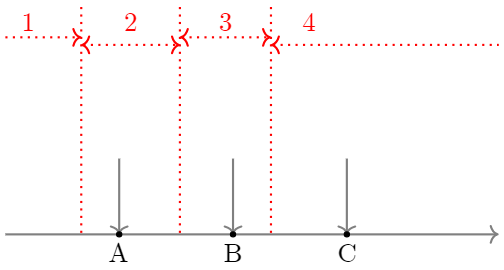
天井効果(床効果)は,回答が一番上(下)の選択肢に偏っている傾向のことです。図 4.1 くらいの多少の効果は気にする必要がないのですが,極端な天井・床効果が生じている項目は除外したほうが良いとされます。 極端な天井・床効果が生じているということは,その項目ではほとんどの人が同じ選択肢を選んでいる,ということです。 通常,心理尺度の項目に対しては 図 4.3 の横軸のように,背後に連続量としての潜在特性を仮定し,各人の回答からその潜在特性の強さを推定します。 つまり各回答者(A,B,Cさん)は自分の潜在特性の強さがどの程度かに応じて,適切な選択肢(1から4)を選択しているはず,と考えます。 これに対して,例えば床効果が生じている状態は 図 4.4 のような状態です。 図 4.3 と比較して,各回答者の位置は変わっていないですが全員が1と回答しています。 実際に私達が観測できるのは回答結果としての「1」のみなので,この項目に「1」と回答したことはその回答者の潜在特性を推定する上でなんの情報も持っていないということになってしまいます。 もちろんごく少数の「極端な人」を識別し「どの程度極端か」を評価する上では有用な項目なので,項目数の制約がなければ入れておいても良いのですが,項目数をなるべく少なくしたいなら,こういった項目は削除したほうが良さそう,と判断できます。 セクション 4.3 では,天井効果・床効果が生じている可能性のある項目に「あたり」をつける簡便な方法を紹介します。
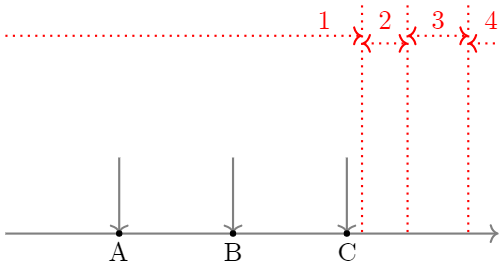
また,項目反応理論などの方法では,こういった極端な項目が含まれていると他の項目の特性の推定にもあまり良くない影響を及ぼしたり,推定自体が不安定になってしまうケースがあります。そういった観点からも,極端な天井効果や床効果が見られる項目は除外したほうが良いのです。
4.1.3 1変数のヒストグラム
年齢など,連続変数の場合は棒グラフよりもヒストグラムのほうが良いでしょう。ヒストグラムはhist()関数で描くことが出来ます。
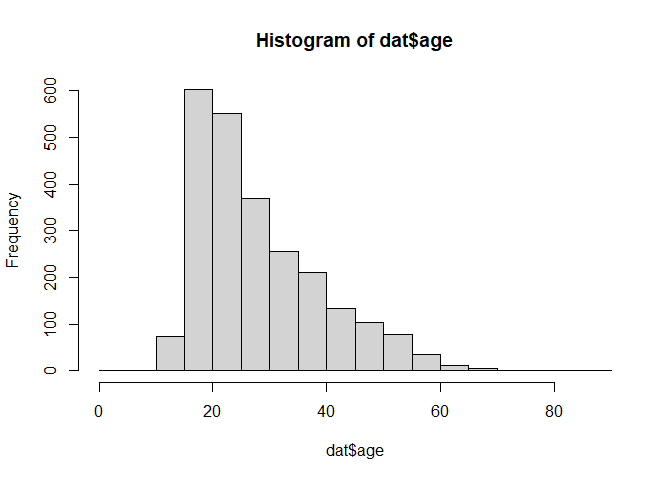
ヒストグラムでは,区切り幅が重要な役割を果たします。 デフォルトでは,スタージェスの公式 (Sturges, 1926) と呼ばれるものに基づいて区切り幅が決定されています。 これは,データの総数を\(n\)と置いた場合に,データの値が取る全範囲を\(1+\log_2 n\)個に等分割する方法です。 したがって,2432人分のデータがあるdatでは\(1+\log_2 2432\)からおよそ12個に等分割された結果が 図 4.5 に表れています。 基本的にはデータの数にあわせていい感じに調整してくれるので良いのですが,場合によっては「年齢を10刻みで区切る」など,区切り幅をきっちり指定したいこともあるでしょう。 これを実現するためには,hist()の引数breaksを指定してあげます。
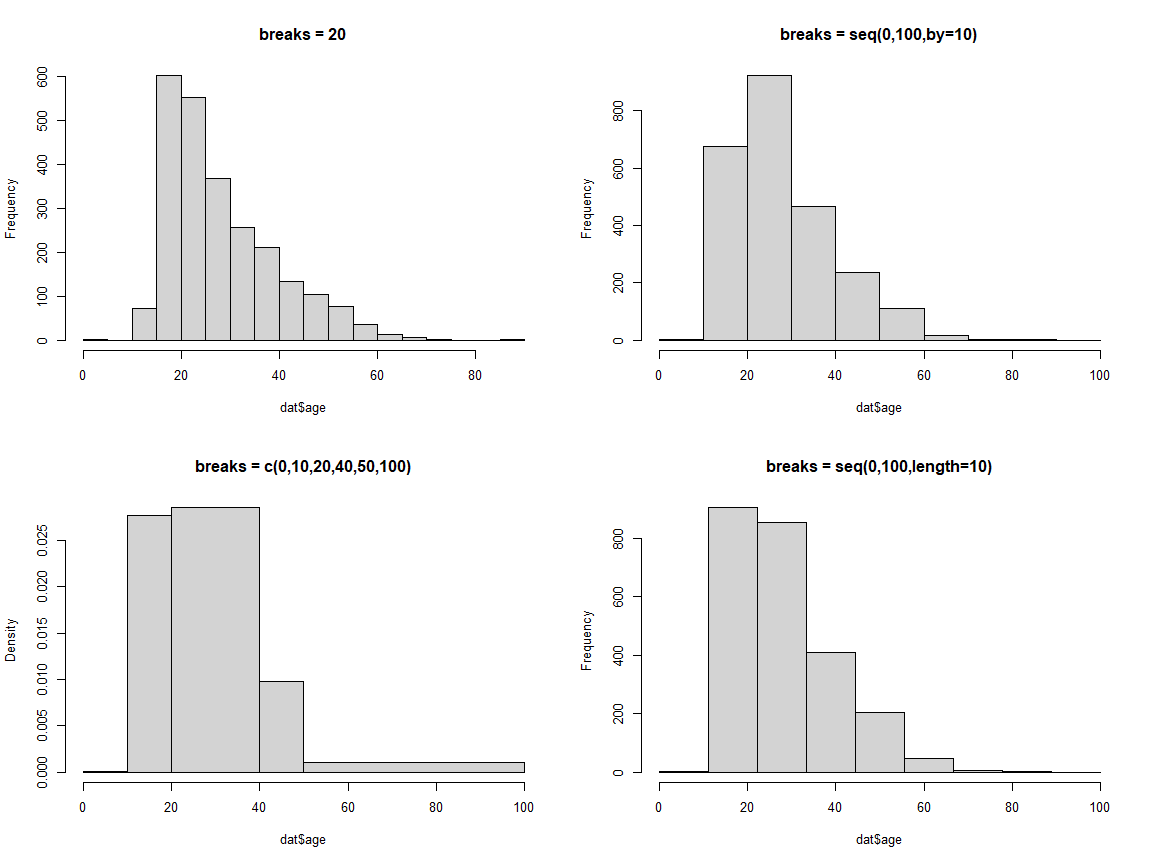
hist()の引数breaksの指定方法は,大きく分けると単一の整数を与える方法と,区切り位置のベクトルを与える方法の2種類があります。 前者の場合は,データの値が取る全範囲をその個数で等分割してくれます。 後者の場合は,等分割以外の区切り方も指定可能( 図 4.6 の左下)ですが,上限と下限がデータの値が取る全範囲を含んでいないとエラーが返ってくるのでご注意ください。
ちなみにbreaksの指定で使用したseq()関数は,等差数列(ベクトル)を作成してくれる関数です。
なお,ageのように整数しか取らない変数についてhist()関数を適用する場合,もう一つ注意点があります。 それは「区切りの端点」です。 hist()関数は,デフォルトではright-closedな区切りを行います。つまり,例えばbreaks = seq(0, 100, by = 10)とした場合には,区切りは「0より大きく10以下(\((0, 10]\))」「10より大きく20以下(\((10, 20]\))」…という感じになります。 したがって, 図 4.6 の右上のヒストグラムは,「10代」「20代」…といわゆる年代ごとに区切ったものとは少し違うものになり,例えばちょうど20歳の人がいわゆる「10代」側に入ってしまうのです。 この点を解決するためには,hist()の引数rightをFALSEにしてあげる必要があります。
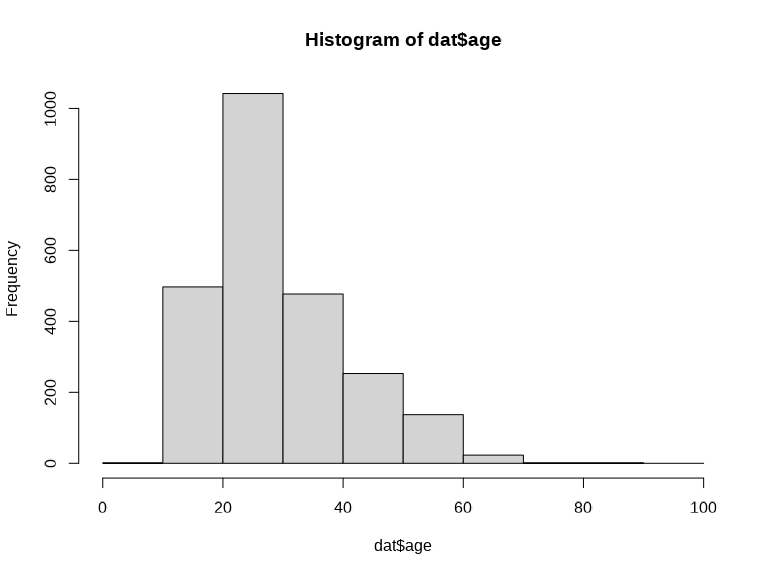
これでようやく,年代ごとに区切った(\([10, 20)\)など)ヒストグラムが描けました( 図 4.7 )。
Sturges (1926) の説明によれば,スタージェスの公式は「二項定理の係数の和」をもとに考えられた値のようです。ここでは,なぜ二項定理が出てくるのかを簡単に説明してみましょう。
まず,ヒストグラムを作りたい変数が正規分布に従っているとします。このとき,正規分布は二項分布で近似することが可能です(二項分布の正規近似の逆)。 とりあえず左右対称な二項分布を作るために,成功確率50%の二項分布\(Binom(\tilde{n}, \frac{1}{2})\)で近似してみましょう。 例えば\(\tilde{n}=4\)とした場合には,\(P(x=k|k=0,1,2,3,4)\)はそれぞれ,\({}_{\tilde{n}}\mathrm{C}_k\times(\frac{1}{2})^4=c(1,4,6,4,1)\times(\frac{1}{2})^4\)となり,左右対称な確率分布になります。 この\({}_{\tilde{n}}\mathrm{C}_k\)の総和が,「二項定理の係数の和」です。
上の\((1,4,6,4,1)\)は,もとのデータがきれいな正規分布に従うとき,それを5等分した各区切りの中に含まれるデータの割合が\((1,4,6,4,1)\)になることを意味しています。 つまり,もしデータが16個だった場合には,ヒストグラムは左から順に\((1,4,6,4,1)\)と並ぶだろう,ということです。 言い換えると,データが16個だった場合には,データを5等分してあげたらいい感じのヒストグラムになりそうだ,と言えるわけです。
ここで一つ重要なポイントがあります。それは,「二項定理の係数」は必ず\(\tilde{n}+1\)個になり,その総和が\(2^{\tilde{n}}\)になる,ということです。 したがって,データの数が\(2^n\)個のときには,ヒストグラムを\(n+1\)個に区切ってあげたらよいだろう,という感じで提案されたのがスタージェスの公式です(たぶん)。
ちなみに,スタージェスの公式はヒストグラムの最適な区切り幅を計算するための公式です。実際のヒストグラムでは,区切り幅は意味のある(または解釈上都合の良い)値として,5や10などキリの良い値になることも多いです。そのため,スタージェスは「意味のある区切り幅のうち,この公式で算出された値を超えない最大の値」にすることを提案しています。
ただし心理尺度の得点などはそもそも値の単位に絶対的な意味がないため,こうした変数に対して用いるような場合にはスタージェスの公式にとりあえずそのまま乗っかってしまっても良い気がします。
4.1.4 2変数の散布図
2変数の散布図を描く場合には,plot()関数が使えます。なお,plot()関数は他にもデータの形式などに合わせて何かしらの図を出してくれたりするので,色んなところでお世話になると思います。
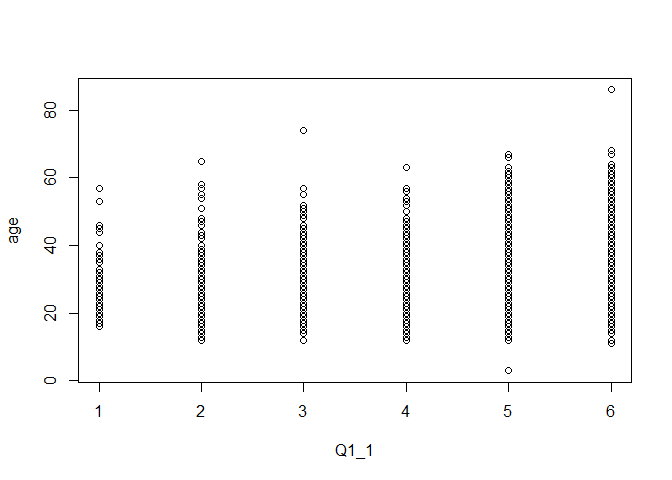
図 4.8 ではQ1_1の取りうる値が6通りしかないため散布図感が薄いですが,一つ一つのマルが各レコードを表しています。
また,2変数のtable()を用いるとクロス表が得られるのですが,これをplot()に与えると違った形の図が得られます。
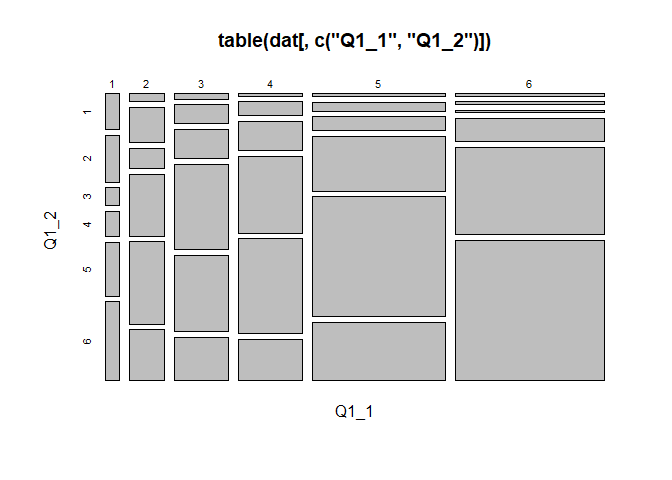
図 4.9 では,それぞれの四角形および行・列の幅が,各選択肢を選んだ人の割合をそれぞれ表しています。
変数の分布をプロットする方法は,他にも色々ありますが(例えば箱ひげ図やバイオリンプロットなど),必要に応じて適切な方法を選べるようになりましょう。 本講義では,あくまでも基本的なプロットの方法のみの紹介にとどめて次に進んでしまいます。
4.2 相関関係のチェック
セクション 2.2 では1変数レベルでの記述統計量をチェックする関数としてsummary()などを紹介しました。 ここでは,同じようにして2変数の関係の記述統計量である相関係数を確認する方法を紹介しておきます。 相関係数はcor()に2つのベクトルを与えることによって計算可能です。これも欠測値がある場合NAを返してくるので,きちんと相関係数を出してほしい場合には適切な引数を与えます。ただし,mean()などの時に使用するna.rmではなくuseという引数を使用します。(説明は後ほど)
cor()には上のように2つのベクトルを与える他に,データフレームをまるごと与えることも可能です。データフレームを一つだけ与えた場合にはそのデータフレーム内の全ての列の相関行列が,データフレームを2つ与えた場合にはデータフレーム同士の全ての列の組み合わせの相関行列が得られます。
ID Q1_1 Q1_2 Q1_3 Q1_4
ID 1.00000000 -0.0442558 -0.04853408 -0.01340771 0.01208236
Q1_1 -0.04425580 1.0000000 0.35277706 0.27444894 0.16169504
Q1_2 -0.04853408 0.3527771 1.00000000 0.49741109 0.35019071
Q1_3 -0.01340771 0.2744489 0.49741109 1.00000000 0.38480054
Q1_4 0.01208236 0.1616950 0.35019071 0.38480054 1.00000000 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
Q1_1 -0.01132405 -0.01088135 0.02365191 0.1161066 0.03943949
Q1_2 0.09785479 0.12411971 0.18509733 0.1523665 0.12848202
Q1_3 0.10989033 0.14186345 0.12557243 0.1261299 0.16038337
Q1_4 0.08963104 0.22389063 0.12966842 0.1739516 0.25181181
Q1_5 0.13115144 0.11412746 0.12906468 0.1290221 0.17094545引数useは,計算に使用するデータを決定します。デフォルトでは"everything",つまり全部使用します。"complete.obs"は,与えたデータフレーム内で欠測値が一つも無いレコードだけを使用して相関を計算します。"pairwise.complete.obs"では各相関を計算する際に,その2変数において欠測値が無いレコードを使用して相関を計算します。つまり相関行列の要素ごとに計算に使用するレコードの数・内容が異なる可能性がある,ということです。
4.2.1 (おまけ)相関関係も可視化してみる
心理尺度に対する多変量解析では,複数の質問項目が同じ構成概念を反映しているかが分析手法のキーとなります。 これを確認する方法の一つとして,後半では信頼性のお話が出てくるわけですが,ここでも少しだけ,相関関係を可視化することでその感覚を掴んでみましょう。
相関行列を可視化するためのパッケージとして,corrplotというパッケージが用意されています。
インストールできたら,早速プロットしてみましょう。
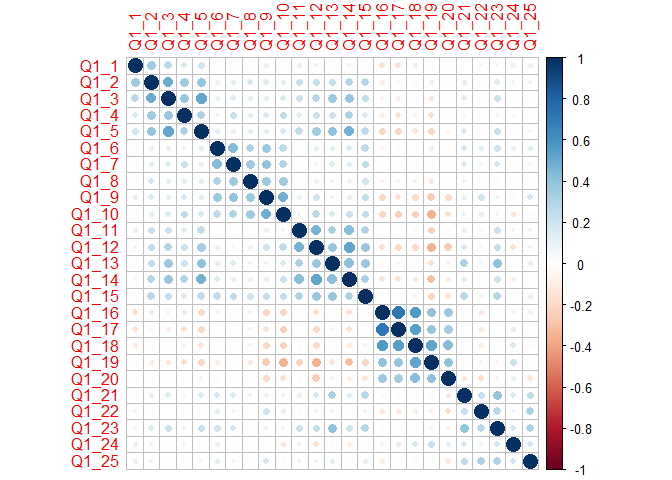
この図では,相関係数が高い変数の組のところほど濃い色(プラスなら青,マイナスなら赤)で表されています。 ざっと眺めるだけでも,いくつかのまとまりがあるのが見て取れる気がします(Q1_16からQ1_20など)。 質問項目間に正の相関が見られるということは,これらの項目の背後には,何か共通の要因があるのかもしれません。 後半で紹介する因子分析 ( チャプター 6 ) では,このような変数間の相関関係をもとに,その背後にあると考えられる要因に迫っていきます。
ちなみに,引数methodを指定することで,プロットの形を変えることも可能です。
4.3 項目分析
まずはじめに,項目単位での「変なやつ」がいないかをチェックしていきます。
4.3.1 天井効果・床効果について検討する
天井効果または床効果が発生しているかの判断について,一発で見抜ける方法というものはありません。 あくまでも一つの基準としてですが,よく言われているのは「平均値 ± 標準偏差が,取りうる値の範囲(今回の例では1から6)を超えている場合」というものらしいです(要出典)。 ただし,いくつかの理由から,この方法だけで機械的に天井・床効果を評価して項目を削除することは望ましくない可能性が高いということは覚えておいてください。
とはいえ,特に変数の数が多くて全ての棒グラフを作って見るのも骨が折れる,という場合には,まずこの判別方法であたりを付けてみるのも良いかもしれません。 ということで,とりあえず上述の基準にのっとって天井効果または床効果の可能性を確認するためには,各変数(列)ごとに平均値や標準偏差を計算する必要があります。 これは普通に考えると,次のようなコードによって実現可能です。
ただ,今回は25項目もあります。上の計算をそれぞれの列にやっても良いのですが効率が悪いので,apply()を使って
ID Q1_1 Q1_2 Q1_3 Q1_4
1396.945312 4.593339 4.801398 4.602385 4.691612
Q1_5 Q1_6 Q1_7 Q1_8 Q1_9
4.548931 4.527138 4.374178 4.301398 4.449013
Q1_10 Q1_11 Q1_12 Q1_13 Q1_14
3.692434 4.020148 3.846217 3.987253 4.414474
Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
4.394326 2.944901 3.519737 3.226151 3.203947
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24
2.972451 4.814967 4.314556 4.454359 4.927632
Q1_25 gender education age
4.528783 1.670230 3.190860 28.582237 とすればよいですね2。 したがって,各列の平均値±標準偏差をまとめて計算したい場合はそれぞれ以下のようになります。
ID Q1_1 Q1_2 Q1_3 Q1_4
2207.424918 5.998918 5.974081 5.908401 6.172146
Q1_5 Q1_6 Q1_7 Q1_8 Q1_9
5.812634 5.758867 5.690390 5.589267 5.825444
Q1_10 Q1_11 Q1_12 Q1_13 Q1_14
5.323572 5.650285 5.458144 5.335440 5.876204
Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
5.733057 4.519407 5.050856 4.819228 4.771938
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24
4.594638 5.936672 5.866132 5.654409 6.116027
Q1_25 gender education age
5.852550 2.140456 4.302853 39.550527 ID Q1_1 Q1_2 Q1_3 Q1_4
586.465707 3.187760 3.628715 3.296368 3.211077
Q1_5 Q1_6 Q1_7 Q1_8 Q1_9
3.285227 3.295409 3.057966 3.013529 3.072583
Q1_10 Q1_11 Q1_12 Q1_13 Q1_14
2.061297 2.390011 2.234291 2.639066 2.952743
Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
3.055594 1.370395 1.988618 1.633075 1.635957
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24
1.350264 3.693263 2.762979 3.254308 3.739236
Q1_25 gender education age
3.205016 1.200004 2.078867 17.613946 天井効果が出ている可能性がある(平均値+SDが6を超えている)変数はQ1_4,Q1_24の2つです。 また,床効果が出ている可能性のある項目は今回は無さそうでした。
ということで,天井効果が出ている可能性のある変数についてプロットしたものが 図 4.12 です。
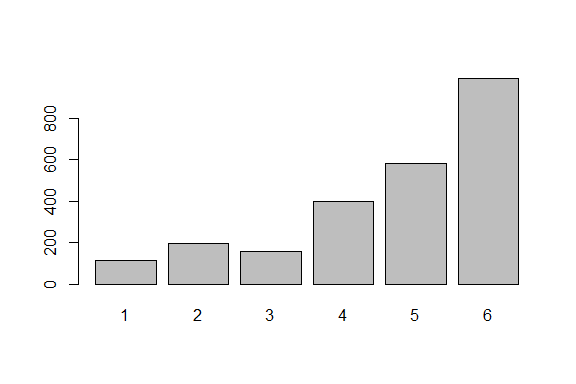
Q1_4
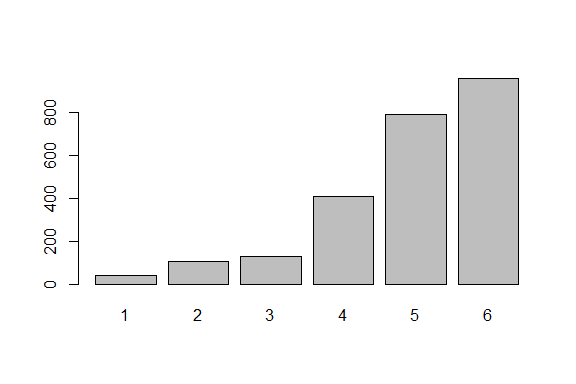
Q1_24
実際に天井効果および床効果が生じていると思われる項目を分析から除外するかについては,定量的な基準(平均±標準偏差)だけで決めるべきではありません。 実際には,この後紹介する妥当性などの観点から項目の内容を吟味したりして,構成概念の定義的に削除しても問題ないかを判断する必要があります。 ちなみに今回の程度であれば,分布が多少偏っているとはいえ,除外するほどの大きな問題とはいえないでしょう。
天井・床効果が問題視されている理由は,多数(というかほとんど)の人が同じ選択肢を選ぶことによって,その項目が持つ「高低を区別する力」が失われてしまうことにあります。 心理尺度を利用する目的は,人々の心理特性の高低を区別することにあります。 したがって,例えば全員が「1」を選んでしまうような項目は,その項目が持つ「高低を区別する力」が全く無いわけですから,尺度としての意味が無い,ということになります。 そういうわけで,事前に天井・床効果が出ていないかをチェックしておけ,という話になっているわけです。
つまり,問題の本質は「端の選択肢が選ばれている割合が高い」ことよりも,「選択された値のバラつきが小さい」ことにあると言えます。 ここで改めて「平均\(\pm\)標準偏差」という基準を考えてみます。 この指標が,回答選択肢の範囲を超えるのは,
- 平均値が端の選択肢に近い
- 標準偏差が大きい
のいずれかに該当する場合です。 前者の場合には,確かに多くの人が端の選択肢を選んでいる可能性が高いでしょう。 一方で,後者の可能性,つまり標準偏差が大きいために引っかかってしまうことも考えられる,というのが「平均\(\pm\)標準偏差」という指標の問題点なのです。
もう少しこの指標について考えるため,現在使用しているdatの中の項目のように6件法の質問項目に対して,以下のような3つの分布があったとしましょう( 図 4.13 )。
- 平均値5.4, 標準偏差0.5
- 平均値5.4, 標準偏差1.2
- 平均値4, 標準偏差0.15
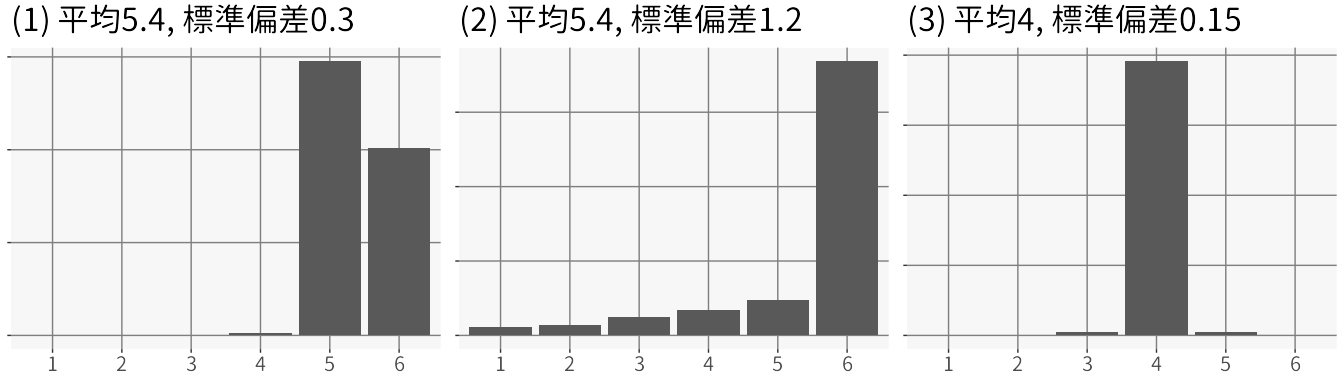
(1)と(2)の分布は平均値は同じなのですが,標準偏差が異なります。 そして「平均\(\pm\)標準偏差」という基準で見ると,天井効果があると判断されるのは,(2)の分布のみです。 ですが,果たして(1)の分布は問題がなく,(2)の分布だけ問題があると言えるでしょうか? むしろ標準偏差が大きいということは,(2)の分布のほうが「高低を区別する力」があると言えるのではないでしょうか? また見方によっては,(2)のほうが1-5の選択肢はきれいに「正規分布の端っこ」のようにも見え,この項目が測定しようとしている心理特性がかなり低い人たちに対してはそれなりに良い分布になっているようにも見えます。 もちろん(1)も,回答が概ね5と6に二分されていることから,この項目が測定しようとしている心理特性の高低を二値判断的には区別する力があるとは言えるかもしれません。
そして問題なのは(3)の分布です。 この分布は,平均値が4と中間的な値に近いため,「平均\(\pm\)標準偏差」という基準では天井効果は無いと判断されます。 しかし,図から明らかに,この項目への回答によって心理特性の高低を区別する力はほとんど無いことがわかります。
以上をまとめると,「平均\(\pm\)標準偏差」という基準には
- 標準偏差が小さい場合には(本当の意味での)天井・床効果を見逃してしまう可能性がある
- 平均値が極端でない場合には,標準偏差が小さいという(本質的な)問題を見逃してしまう可能性がある
といった問題があると考えられます。
ということで,私が 図 4.12 のようなレベルの天井効果について除外しなくても良いと考えている理由は,こうした項目は少なくとも特性値の低い人を区別する力は持っているためです。
心理尺度への回答は,その背後にある心理特性(社交性や誠実さなど)の強さを反映して決まっていると考えられます。 つまり天井効果(床効果)が起きているような項目では,「その心理特性が一定レベル以上(以下)の強さの人はみんな端の選択肢を選んでいる」状態なわけです。 その「一定レベル」の閾値を仮に30とすると,天井効果が起きている項目は,レベル80の人とレベル90の人はどちらも最大値の選択肢を選ぶために区別ができないわけですが,少なくともレベル10の人とレベル20の人は区別できるだろう,というわけです。 したがって,多少の天井/床効果が起きている程度で,その項目には全く意味がない,ということにはならないだろう,というのが私の考えです。
ただし,天井/床効果が起きていない項目と比べると,( 図 4.13 の真ん中の分布のように)1項目が持つ「高低を区別する総合力」は低い可能性が高いので,例えば尺度を新規作成する際や,質問票にいれることのできる項目数に厳しい制限があるならば,どちらかといえば天井/床効果が起きていない項目を選んだほうが良いと思います。 一方で,上述の理由から,既存の尺度を使って,しかも既に取った後のデータの分析を行う段階ならば,そこでわざわざ多少の天井/床効果での項目削除はしなくても良いのではないか,と思っています。
項目の除外判断で重要となるのは,天井/床効果が生じているかよりも,回答が一箇所に集中しすぎていないかだと思っています。 もしも 図 4.13 の右の分布のように,全ての人がちょうど中間の選択肢を選んでいた場合,天井/床効果はいずれも生じていなくても項目としては明らかにおかしなものになっているはずです。 そう考えると,単に標準偏差が異様に小さい項目が無いかを見ておけば良いような気がしています。
個人的な見解としては,天井・床効果を検出するための基準としては,「平均値±標準偏差が取りうる値の範囲を超えているか」よりも,「標準偏差が異様に小さいか」を見ていくほうが良いのではないかと思っています。 つまり,すべての項目について標準偏差を計算してみて,小さい方から順番に見ていけば良い気がします。
また別の考え方としては,最も多く選ばれている選択肢の選択率を見るというのもありだと思います。経験的には,1つの選択肢に全体の80%以上の人が集中しているような項目は,回答が一箇所に集中しすぎている可能性が高いと思います。 ただこれも最終的にはケースバイケースで,80%を超えていても問題ない場合もあるでしょうし,逆に80%を超えていなくても問題がある場合もあるでしょう。 どれくらいケースバイケースかというと,例えば医療・臨床分野の尺度においては,尺度得点が最小値・最大値の人が15%いたらあまり良くないと判断されることもあるようです (Terwee et al., 2007)。 これは,医療・臨床分野では,健康状態の変化を捉えることが重要であるため,最初から尺度得点が最小値・最大値の人が多いと,変化を捉える力が弱くなってしまうといった理由もあるようです。
つまるところ,その項目を取り除くかどうかは,可能であれば項目の内容を吟味して,また実際に取り除く場合と取り除かない場合で分析結果がどのように変わるかを見てみるなどして,総合的に判断する必要があると思います。
4.3.2 I-T相関
ここでは大前提として,心理尺度では複数の項目が同じ構成概念を測定しようとしているはずだというところから出発して考えます。 このとき,ある項目が,同じ尺度内の他の項目と確かに同じ構成概念を測定しているならば,他の項目の得点との相関は高いはずです。ということは当然,合計点との相関も高いだろうという予測が立ちます。 この考えに基づいて算出される指標が,各項目の値と,尺度の合計点の相関であるI-T相関 (Item-TestまたはItem-Total)です。 他の項目との一貫性という点では,後述する信頼性の分析の一部という見方もできます3。
I-T相関を出すためには,まず合計点を出す必要があります。これはapply()を使えば簡単に出来ます。最も簡便な尺度得点としてそのまま他の変数との関係を見る分析にも使えたりするので,ここで各因子ごとに合計点を作成してdatに追加しておきましょう。 なおRではほとんどの場合,データフレームの存在しない列名を指定して代入すると,新しい列を追加してくれます4。
# 列の指定の仕方はいろいろありました
# ↑復習を兼ねて,わざと異なる方法で列を指定しています
# Agreeableness
dat[, "Q1_A"] <- apply(dat[, paste0("Q1_", 1:5)], 1, sum)
# Conscientious
dat$Q1_C <- apply(dat[, paste0("Q1_", 6:10)], 1, sum)
# Extraversion
dat[, "Q1_E"] <- apply(dat[, paste0("Q1_", 11:15)], 1, sum)
# Neuroticism
dat["Q1_N"] <- apply(dat[, paste0("Q1_", 16:20)], 1, sum)
# Openness
dat$Q1_O <- apply(dat[, paste0("Q1_", 21:25)], 1, sum)
# 一旦確認
head(dat) ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10 Q1_11 Q1_12
1 1 5 4 3 4 4 2 3 3 3 3 4 4
2 2 5 4 5 2 5 5 4 4 4 3 6 6
3 3 2 4 5 4 4 4 5 4 5 2 5 3
4 4 3 4 6 5 5 4 4 3 2 2 2 4
5 5 5 3 3 4 5 4 4 5 4 5 5 5
6 6 1 6 5 6 5 6 6 6 6 4 5 6
Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19 Q1_20 Q1_21 Q1_22 Q1_23
1 3 4 4 3 4 2 2 3 3 1 3
2 6 4 3 3 3 3 5 5 4 5 4
3 4 4 5 4 5 4 2 3 4 5 5
4 4 4 4 2 5 2 4 1 3 4 4
5 5 4 5 2 3 4 4 3 3 4 4
6 6 5 6 3 5 2 2 3 4 4 5
Q1_24 Q1_25 gender education age Q1_A Q1_C Q1_E Q1_N Q1_O
1 4 4 1 NA 16 20 14 19 14 15
2 3 4 2 NA 18 21 20 25 19 20
3 5 5 2 NA 17 19 20 21 18 24
4 3 2 2 NA 17 23 15 18 14 16
5 3 4 1 NA 17 20 22 24 16 18
6 6 6 2 3 21 23 28 28 15 25合計点が出来たら,後は相関係数を計算するだけです。ですが,ここで計算するべき相関係数は,普通の(ピアソンの積率)相関係数ではありません。
カテゴリカル変数の相関
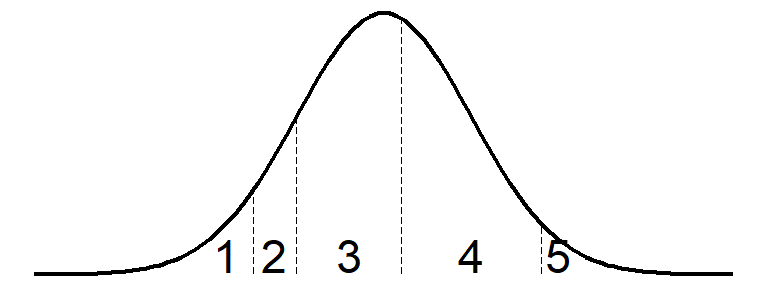
各項目への回答は,本来連続量である潜在変数(因子)の強さによって規定されます。実際に観測できる項目反応(5件法なら1から5の数字)は,この潜在変数を適当なところで打ち切ってカテゴリ化された値とみなせるわけです。 図 4.14 はその関係を表した図です。潜在変数は通常,正規分布に従うと仮定されます。心理尺度への回答データを考える際には,正規分布の仮定のもとで,潜在変数の強さの程度に応じて,回答者は自分にあった強さの選択肢を選んでいる,というように考えます5。
ということは,合計点6との相関係数を計算する場合,本来は項目への回答そのものではなく,背後にある潜在変数の値で計算したほうが良いのです。むしろそうしないと,連続量をカテゴリに落とし込むことで失われる情報のせいで,本来の相関係数よりも低い値が算出されてしまいます。
今回はポリシリアル相関(polyserial correlation)というものを使います。これは,(多値)カテゴリカル変数の背後にあると想定される連続量と,連続変数との相関係数です。 他にも,同じような考え方の特殊な相関係数がいくつかあり,それらは 表 4.1 のようにまとめられます。
| 連続 | 多値 | 二値 | |
|---|---|---|---|
| 連続 | ピアソンの積率相関 | ポリシリアル相関 | 点双列相関 (バイシリアル相関) |
| 多値 | ポリシリアル相関 | ポリコリック相関 | ポリコリック相関 |
| 二値 | 点双列相関 (バイシリアル相関) |
ポリコリック相関 | テトラコリック相関 |
これらの特殊な相関係数を計算するためのパッケージとしては,polycorパッケージというものがあります。
今回はポリシリアル相関を計算するため,polyserial()を使用しましょう7。 少し注意が必要な点として,polyserial()関数では
- 第1引数(
x)に入れた変数は自動的に連続変数として扱われる - 第2引数(
y)に入れた変数は自動的にカテゴリカル変数として扱われる
つまり引数の順番が変わると計算結果が変わってしまいます。 そして,このように引数の順番が重要な関数は,apply()関数と組み合わせて使用する場合にやや面倒なことが起こります。 図 4.15 に,簡単な概要をまとめたものを用意しました。 apply(X, MARGIN, FUN)では,MARGINの方向に分割されたXを,それぞれFUNで指定した関数の第一引数に与えるという挙動をします。 つまりFUNにpolyserialを指定した場合,Xで与えたものは自動的に連続変数として扱われざるを得ないのです。

polyserial()関数をapply()関数の中で呼んだとき
こればっかりはapply()関数の仕様のため,たぶんどうしようもありません。 そこでやや面倒ですが,回避策としてpolyserial()関数の引数の順番を入れ替えたものを別の関数として先に定義しておくことにします。
I-T相関という場合,実は2種類の相関係数が考えられます。一つはいま計算した「合計点との相関」です。しかし今回のように項目数が少ない場合,「合計点」はその項目自身の影響を結構強く受けていると考えられます。そこで,「合計点から自身の得点を引いたものとの相関」I-T相関として考えることもあります。例えばQ1_1のI-T相関であれば,Q1_2からQ1_5までの4項目の合計点との相関を見る,ということです。
「合計点から自身の得点を引いたものとの相関」を見る場合,先程よりはやや難しくなります。これもやり方はいくつかあると思いますが,ここでは関数を定義してやってみましょう。
当然ですが,自身の得点を引いたものとのI-T相関のほうが低くなりました。ただ今回はいずれの項目も問題ないレベルのI-T相関を示しています。(当然と言えば当然ですが)サンプルデータなのでかなりきれいです8。
ちなみにI-T相関が低いということは,それすなわち項目が悪い,というわけではありません。あくまでも他の項目との相関が低いだけです。ただ,I-T相関が低い項目が入っている場合,因子分析をしても思った通りに因子がまとまらなかったり,項目反応理論でもうまくパラメータ推定ができない可能性が高くなります。 そのため,内容次第ではありますがI-T相関が低い項目があればこの段階で分析から除外する,ということもあります。実際のところどの程度低かったら問題視されるかの明確な基準は多分無いのですが,経験的には自身の得点を引いたものとのI-T相関が0.2から0.1を下回ると,相当厳しいケースが多いです。
カテゴリカルな相関係数の計算方法の考え方
上述したようなカテゴリ変数に対する相関係数では, 図 4.14 に示したように,各項目への回答の背後に正規分布に従う連続量があると仮定します。 ここで,2つの二値項目(当てはまる/当てはまらない)への回答\(x_i,x_j\)について,(点双列)相関係数の出し方を説明します。 もちろん多値項目に対する相関係数も原理は同じです。
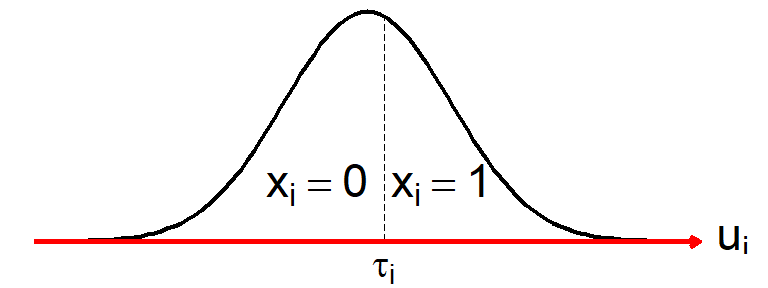
二値項目その背後にある連続量をそれぞれ\(u_i,u_j\)としておきます。 カテゴリカルな相関係数では,連続量が閾値を超えていたら1, 超えなければ0と回答している,と考えるので,各項目についての閾値をそれぞれ\(\tau_i,\tau_j\)と置くと,項目への回答と連続量の関係性を以下のように表すことができます。 \[ \begin{aligned} x_i = \begin{cases} 0 & u_i < \tau_i \\ 1 & u_i \geq \tau_i \end{cases} \;\;\;\;\;\; x_j = \begin{cases} 0 & u_j < \tau_j \\ 1 & u_j \geq \tau_j \end{cases} \end{aligned} \]
\(u_i\)に関して,ここまでの関係を表したものが 図 4.16 です。 同様の関係が\(u_j\)についても存在しているとします。
いま知りたいのは,2つの回答そのものの相関係数\(r_{x_i,x_j}\)よりも,その背後にある連続量同士の相関係数\(r_{u_i,u_j}\)です。 これを計算するためには,2つの項目についての 図 4.16 に2変量正規分布の図を組み合わせて,実際に得られる回答の割合を考えます。 図 4.17 の2つの図は,いずれも\((\tau_i,\tau_j)=(0.2,-0.8)\)として作図したものです。
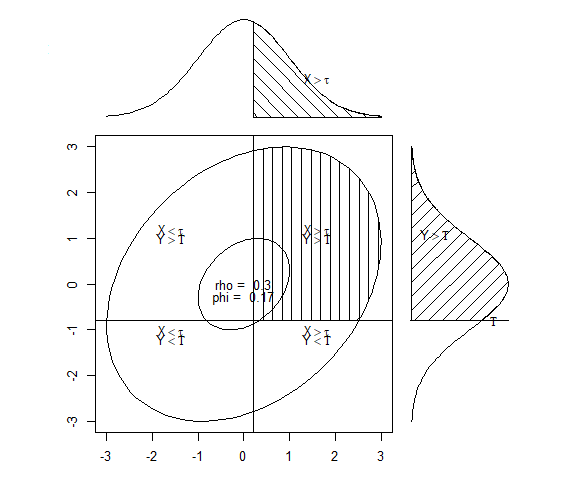
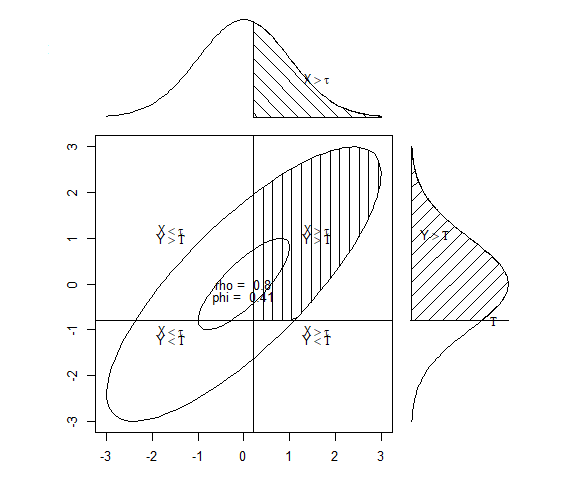
周辺尤度(各図の上と右にある正規分布)にはいずれも標準正規分布を仮定して,それぞれ\(\tau_i=0.2\)以上および\(\tau_j=0.8\)のところが塗りつぶされています。 いま,各図の中の楕円は2変量正規分布の確率密度(左:相関弱め,右:相関強め)を表しています。 したがって楕円のうち塗りつぶされている箇所(右上)は,2変量正規分布において\(\tau_i=0.2\)以上かつ\(\tau_j=0.8\)となる確率=2項目の両方に「当てはまる」と回答する確率を表しています。 図からもわかるように,2変量正規分布の形は相関係数によって変化するため,2つの閾値(\(\tau_i=0.2\)と\(\tau_j=0.8\))で区切られた4つの区間の面積は相関係数によって変わります。
そして観測されたデータにも,2つの二値項目に対する回答の組み合わせが4パターン存在しうるので,それぞれの出現割合(\(0\leq \pi_{\cdot\cdot}\leq 1\))を 表 4.2 のようにまとめておきます。
| \(x_j=0\) | \(x_j=1\) | |
|---|---|---|
| \(x_i=0\) | \(\pi_{00}\) | \(\pi_{01}\) |
| \(x_i=1\) | \(\pi_{10}\) | \(\pi_{11}\) |
これで材料が出揃いました。 カテゴリ変数に対する相関係数では,図 4.17 の楕円の4つの領域の確率と 表 4.2 の4つの\(\pi\)の割合が一致するように各項目の閾値\(\tau_i,\tau_j\)および相関係数\(r_{u_i,u_j}\)を求めます。 例えば「100人中25人が\((1,1)\)と回答した」という場合には\(\pi_{11}=0.25\)となるので, 図 4.17 の楕円のうち塗りつぶされている部分(右上)の確率も0.25になるように,\((\tau_i,\tau_j,r_{u_i,u_j})\)の3つを計算し,得られた\(r_{u_i,u_j}\)の値が(点双列)相関係数となるわけです。
実際のアルゴリズムでは,これをもう少し簡便にした二段階推定法が用いられることが多いようです。 二段階推定法では,まず第一段階で閾値\(\tau_i,\tau_j\)を各回答の出現割合から決定してしまいます。 例えば「100人中30人が\(x_i=1\)と回答した」という場合には,標準正規分布のなかで上位30%の人が\(u_i\geq\tau_i\)であったと考えられます。 したがって,閾値\(\tau_i\)は,標準正規分布における上側30%の( 図 4.16 において点線より右側の面積が30%になる)点となり,これを計算するとおよそ0.524と求めることが出来ます。 そして第二段階では,第一段階で得られた閾値を固定して,相関係数\(r_{u_i,u_j}\)のみを計算します。
4.3.3 G-P分析・トレースライン
Good-Poor分析とは,特に学力テストの文脈で用いられることのある分析方法です。テストの場合,合計点が高い人ほどGood,低い人ほどPoorとされるわけですが,仮にある項目がテスト全体と同じものを測定しているならば,合計点が高い人ほど正答率が高く,低い人ほど正答率が低い,ということが言えそうです。…この考え方,先程のI-T相関と非常に良く似ていますね。
G-P分析では,合計点によって全回答者を3群程度に分け,上位(Good)群と下位(Poor)群での正答率の差をチェックします。もしも正答率に差があれば,たしかにその項目はそのテスト全体が言うところの上位と下位を弁別できていそうだぞ,ということになるわけです。
トレースラインは,G-P分析のときと同じように,合計点によって全回答者をいくつかの群に分け,各群での各選択肢の選択率をプロットしていきます。一番左から順に,得点の低い群から並べていった時に,誤答選択肢の選択率は右肩下がりに,正答選択肢の選択率が右肩上がりになっていれば,たしかにその項目はそのテスト全体が言うところの上位と下位を弁別できていそうだぞ,ということになるわけです。
図 4.18 は,仮想的な5件法の項目に対するトレースラインの例です。 この例では,データを合計点で5等分しています。 したがって,各プロットの一番左は「合計点の下位20%の人たちの,この項目への回答の平均点」を表しているわけです。 では一つずつ図を見ていきましょう。
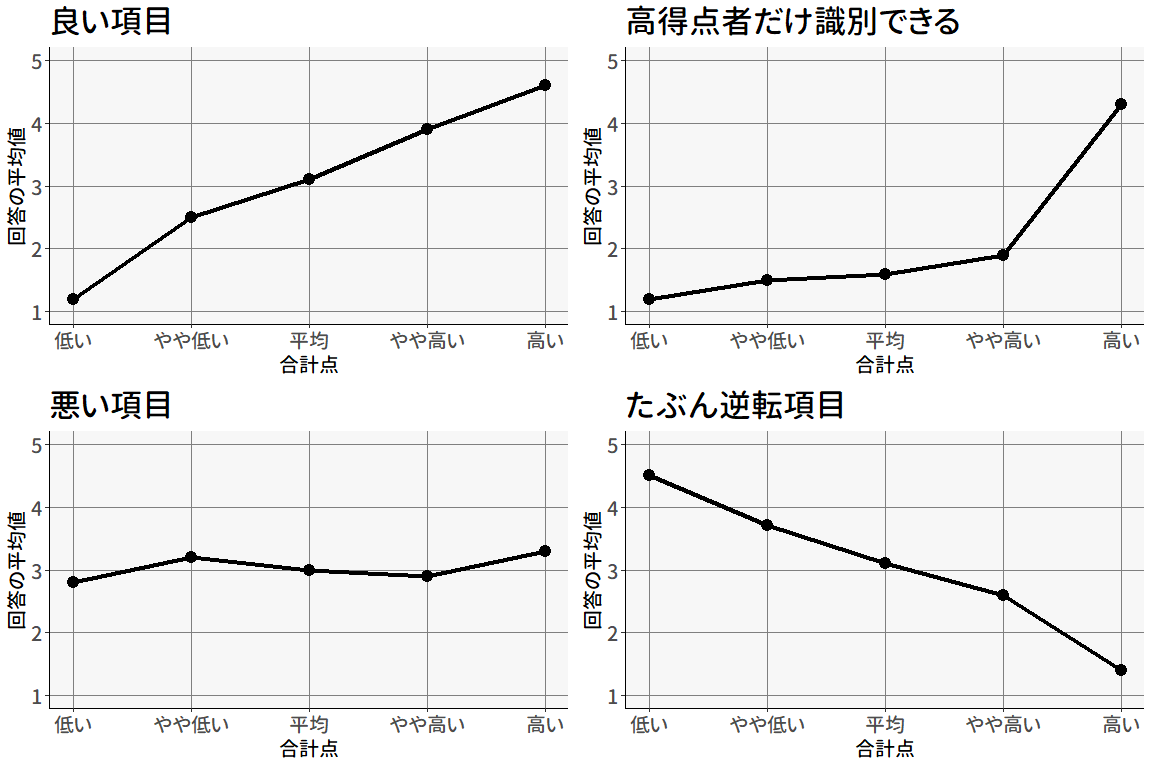
図 4.18 の左上の図は,合計点が高い人ほどこの項目にも高い点をつけているため,良い項目だと判断できます。 言い換えると,この項目に対して何と回答したかによって,その人の合計点(その背後にある潜在特性)の高低を正しく評価できている,ということです。 このような項目では,I-T相関も高く出ることでしょう。
図 4.18 の右上の図は,合計点の最上位層のみが高い点をつけていて,他の人達は軒並み低い点をつけている項目です。 このような項目は,床効果が出ている項目と見ることが出来ます。 一方で,この項目は「高得点か否か」を識別できる項目としてはよく機能しているため,この程度の床効果では削除する必要はない可能性が高いでしょう。 I-T相関はちょっと低くなるかもしれませんが,G-P分析を行えば問題ない結果が出るはずです。
図 4.18 の左下の図は,合計点の高低にかかわらず平均値が概ね同じ値になっています。 一般的には,このような項目が悪い項目と判断されます。 この項目に何と回答するかが,その人の合計点(その背後にある潜在特性)の高低と無関係になっているということは,この項目への回答が潜在特性の高低の推定に役立っていないということです。 このような項目ではI-T相関は低く,G-P分析もダメダメになると思われるので,事前に削除を検討しても良いと思います。
図 4.18 の右下の図は,これまでと違って右下りになっています。 ふつう心理尺度では,すべての項目は同じ特性を反映していると考えているため,単一項目への回答と合計点は正の相関になるはずなので,ちょっとおかしいです。 最もありえるのは「逆転項目の処理忘れ」でしょう。 一方で,もしも逆転項目のつもりではない項目でこのような関係が見られた場合は,ワーディングなどに問題を抱えている可能性が考えられるので,使用を慎重に検討したほうが良いかもしれません。
トレースラインの作り方
ここからは,実際に平均点のトレースラインを作成してみたいと思います。 トレースライン作成のために必要な工程は以下のとおりです。
- 合計点を用いてデータをいくつかのグループに分ける
- 各グループについて,特定の項目への回答の平均値を出す
- X軸を1. で求めたグループ(小さい順),Y軸を2. で求めた平均値としてプロットする
工程1. では新しい材料として,Hmisc::cut2()関数を使用します。 この関数は,与えられたベクトルの中身を小さい順に並び替えてg等分したときに,各レコードがどのグループに入るかを教えてくれる関数です。
Hmisc::cut2] データを等分する
[1] 19.248 21.000 19.248 22.511 19.248 22.511 22.511 14.317 27.000
[10] 22.511 22.511 24.000 14.317 21.000 22.511 21.000 19.248 22.511
[19] 14.317 24.000 28.466 27.000 24.000 25.000 19.248 28.466 19.248
[28] 24.000 26.000 28.466 26.000 25.000 14.317 26.000 19.248 30.000
[37] 22.511 27.000 24.000 19.248 28.466 30.000 14.317 25.000 19.248
[46] 30.000 28.466 26.000 22.511 19.248 30.000 22.511 14.317 19.248
[55] 25.000 21.000 21.000 21.000 19.248 28.466 22.511 14.317 22.511
[64] 27.000 24.000 19.248 25.000 22.511 26.000 28.466 25.000 14.317
[73] 25.000 25.000 19.248 24.000 28.466 25.000 22.511 26.000 27.000
[82] 26.000 26.000 24.000 22.511 27.000 25.000 19.248 14.317 26.000
[91] 19.248 19.248 19.248 22.511 22.511 19.248 28.466 14.317 27.000
[100] 25.000
[ reached 'max' / getOption("max.print") -- omitted 2332 entries ]
10 Levels: 14.317 19.248 21.000 22.511 24.000 25.000 26.000 ... 30.000cut()関数の場合
2026年5月14日まで,cut()関数がデータを等分するものだと勘違いして以下の説明をしていました。 cut()関数は,データを人数で等分するのではなく,最小値と最大値の間を等分(seq(min, max, length.out = breaks))した上で各レコードがどの区分に入るかを返す関数でした。 今回のデータであれば多分これでも大きな問題は無いのですが,分布が偏っている場合などには非常に小さいグループが出来てしまう可能性があるため,今回はHmisc::cut2()を使用するように修正しました。 ただcut()関数についても,これはこれで使い道があると思うので,こちらのバージョンの説明も残しておきます。
cut] データを等間隔に分割する
[1] 6 7 6 8 6 8 8 4 9 8 7 8 4 7 7 7 6 8 3 8 10 9
[23] 8 8 6 10 6 8 9 10 9 8 5 9 6 10 8 9 8 6 10 10 5 8
[45] 6 10 10 9 7 6 10 8 5 6 8 7 7 7 6 10 7 3 8 9 8 6
[67] 8 8 9 10 8 5 8 8 6 8 10 8 7 9 9 9 9 8 8 9 8 6
[89] 3 9 6 6 6 7 8 6 10 1 9 8
[ reached 'max' / getOption("max.print") -- omitted 2332 entries ]
Levels: 1 2 3 4 5 6 7 8 9 10試しに,89-100行目の人(上の出力で一番下の行に表示されている人たち)のdat$Q1_Aの値とcut()関数の返り値を見比べてみると,確かにdat$Q1_Aが大きいID=106番の人のcutが10になっており,またその次の(dat$Q1_Aが小さい)108番の人のcutは確かに小さな値(1)になっていることがわかります( 表 4.3 )。
Q1_A)とcut()の返り値
| ID | Q1_A | cut | |
|---|---|---|---|
| 89 | 97 | 11 | 3 |
| 90 | 98 | 26 | 9 |
| 91 | 99 | 19 | 6 |
| 92 | 100 | 20 | 6 |
| 93 | 102 | 18 | 6 |
| 94 | 103 | 22 | 7 |
| 95 | 104 | 23 | 8 |
| 96 | 105 | 18 | 6 |
| 97 | 106 | 29 | 10 |
| 98 | 108 | 6 | 1 |
| 99 | 109 | 27 | 9 |
| 100 | 110 | 25 | 8 |
工程2. において便利なのがaggregate()関数です。 この関数は,指定した変数の値ごとにグルーピングしたうえで,それぞれのグループに対して計算を行ってくれる関数です。 ちょっとわかりにくいと思うので,以下のコード例を見てみてください。
aggregate(): 指定した変数の値でグルーピングしてから関数を適用する
aggregate()関数には何通りかの記法があるのですが,ここではformulaを使った記法で紹介します9。 もともとformulaは回帰分析の式(\(y=b_1x+b_0\))に合わせた形で,左辺に被説明変数,右辺に説明変数を書くというR特有の記法の一つです。 aggregate()関数では,この記法を利用して左辺に計算対象の変数名,右辺にグルーピング対象の変数名を書き,その後ろに「どのデータについて実行するか」「どの関数を実行するか」をそれぞれ書いていきます。 したがって先程のコードは,「datについて,educationの値ごとにグループを作り,Q1_1のmean(na.rm=TRUE)を計算してくれ」という指示になっていたわけです。
ちなみにaggregate()では,複数の属性について同時にグルーピングを行い関数を適用することも出来ます。 この場合,回帰分析の説明変数を追加する要領で,右辺に変数名を足していくだけでOKです。 ここでは使いませんが,以下のように「gender\(\times\)educationごとの平均点」といった計算も可能です。
話を戻すと,今やりたいことは「Q1_Aの値によって分割された各グループについて,特定の項目への回答の平均値を出す」でした。 aggregate()を使えば,以下のように実装することが出来ます。
あとはこれをプロットするだけです。
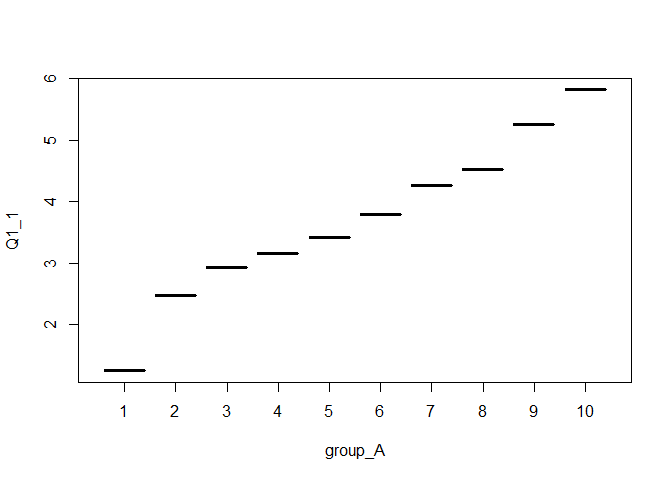
group_meanには2つの変数が入っているので,これで散布図が書けると思ったのですが,なんだか思ってたのとはちょっと違う図( 図 4.19 )が出てきました。 実はこれは,aggregate()関数のグルーピングに使用していた変数group_Aが,numeric型ではなくfactor型になってしまっていたためです。
plot()関数は,2つの変数が両方ともnumeric型であれば散布図を描いてくれるのですが,今回のケースではgroup_Aがfactor型になっているために「グループごとの分布を箱ひげ図で表示する」という挙動をしてしまったのです(グループごとの値が1つしかないので箱もひげも無いですが)。 Rではこのように,関数の挙動によって想定していたものと異なる型の変数に勝手に置き換わってしまうことがちょくちょくあるので,ここは逃げずにきちんと変数の型を変更してから再度プロットしましょう10。
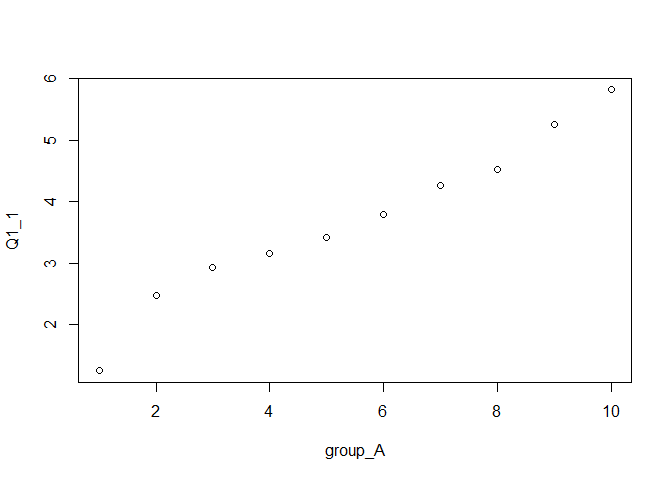
factor型の変数をnumeric型に変換する際の注意点
factor型の変数をnumeric型に変換する際には,character型への変換を挟むかどうかによって結果が異なります。 というのは,Rではfactor型の変数は「水準(levels)」を持つ型として扱われており,表向きにはその水準の順序を表す数値としても扱われているためです。 具体的には, 表 4.4 のように,水準の順序とラベルの対応表のようなものが存在していると考えます。 そしてデータフレームの中にはこの水準の順序(group_A列)を表す数値が入っていながら,コンソールなどに表示されるときには自動的にラベル(level列)が表示される,というなかなかややこしい仕組みになっているのです。
| level | group_A |
|---|---|
| 14.317 | 1 |
| 19.248 | 2 |
| 21.000 | 3 |
| 22.511 | 4 |
| 24.000 | 5 |
| 25.000 | 6 |
| 26.000 | 7 |
| 27.000 | 8 |
| 28.466 | 9 |
| 30.000 | 10 |
このため,factor型の変数を直接numeric型に変換すると,水準の順序を表す数値(group_A列の値,つまり今回の例では1から10)が入ってしまいます。
これに対して,先にcharacter型に変換してからnumeric型に変換すると,まずcharacter型に変換したタイミングで水準のラベル(level列の値,つまり今回の例ではグループの平均値)に置き換わってくれるので,結果的にグループの平均値に置き換えることができるのです。
あとは 図 4.20 の点どうしを線で繋げば, 図 4.18 で見たようなトレースラインの完成です。 そのためには,以下のように引数typeを与えてあげると良いでしょう( 図 4.21 )。
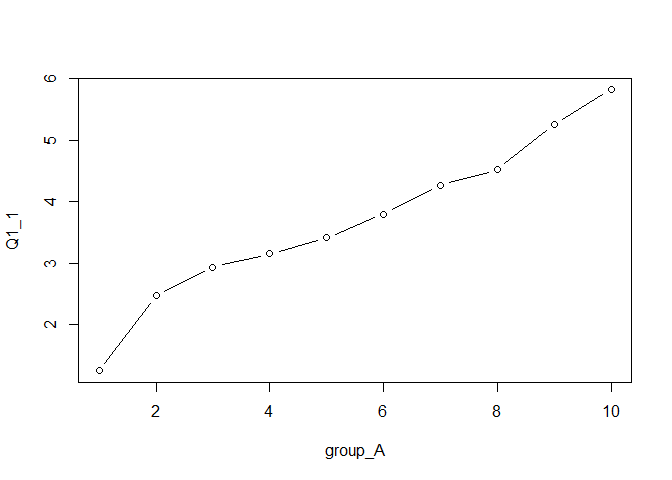
引数typeとして良く用いられるのは,p(点をうつ),l(線で結ぶ),b(pとlを両方),n(何も表示しない)あたりでしょうか。 他にもplot()には「線の太さ・色・形」「点の大きさ・色・形」「軸の名前」「図の上部に表示する名前」「目盛りの大きさ」を始めとして様々な設定が可能ですが,ここでは取り上げません11。
完成したQ1_1についてのトレースライン( 図 4.21 )は, 図 4.18 でいえば左上のように,いい感じに右上がりの線になっています。 したがって,Q1_1の回答は,因子Aの他の項目Q1_2からQ1_5と同じ傾向にある,言い換えると,これらの項目と概ね同じような因子について尋ねている項目であると言えそうです。
…ということで余裕があれば,この調子で全ての項目についてトレースラインを描いてみてください。
【おまけ1】こういうときこそ関数化
トレースラインを作成する方法はわかりましたが,実際にはこの作業を項目の数だけ行う必要があります。 一つ一つの工程はシンプルですが,いちいち複数の工程をこなす必要があり,結構面倒ですよね。 こういったときこそ,同じ作業を関数化することを考えてみましょう。 以下に,トレースライン作成のコードを関数化するための(私なりの)手順を紹介しておきます。 「関数化」というのは,基本的に同じ作業を何回も書くのが面倒だという面倒くさがりを救済するための技術なので,「われこそは面倒くさがりだ」という人は是非習得してください12。
関数化する場合も,最初は普通にコードを作成します。 ということで,先程紹介したトレースライン作成のコードを以下にまとめて示しておきます。
# 1. 合計点で10個にグルーピングしたものをdatに追加する
dat$group <- cut2(dat$Q1_A, g = 10, levels.mean = TRUE)
# 2. ある項目について,グループ平均値を出す
group_mean <- aggregate(Q1_1 ~ group, dat, mean, na.rm = TRUE)
# 3.1 factor型になっているところをnumericまたはinteger型に修正する
group_mean$group <- as.numeric(as.character(group_mean$group))
# 3.2 プロットする
plot(group_mean, type = "b")きちんと目的を果たせるコードが書けたら,このコードのうち変わる部分はどこかを考えます13。 上記のコードでいえば,「どの項目についてトレースプロットを描くか」と「cut2()でどの合計点(A,C,E,N,O)を使うか」の2点が変わるところです。 そこで,この「変わる部分」を一旦変数に代入します。
そして,作成した変数x, totalを使って先程のコードを置き換えていきます。
# 列をdat$の代わりにchr型で指定する
# 1. 合計点で10個にグルーピングしたものをdatに追加する
dat$group <- cut2(dat[, total], g = 10, levels.mean = TRUE)
# 2. ある項目について,グループ平均値を出す
group_mean <- aggregate(x ~ group, dat, mean, na.rm = TRUE)
# 3.1 factor型になっているところをnumericまたはinteger型に修正する
group_mean$group <- as.numeric(as.character(group_mean$group))
# 3.2 プロットする
plot(group_mean, type = "b")ただ,実際にやってみるとわかりますが,実はこのままではうまくいきません。
Error in model.frame.default(formula = x ~ group, data = dat): variable lengths differ (found for 'group')エラーメッセージを見てもわからないと思いますが,実はaggregate()関数の第一引数をformulaとして与える場合,「Q1_1 ~ group」のように" "でくくらない(character型ではない)必要があります14。 しかし,x <- "Q1_1"を用いてx ~ groupを書き換えると,「"Q1_1" ~ group」となってしまうために,正しくformulaとして解釈されないのです。
この場合の対処法は,formula()関数を用いることです。例えば以下のように,第一引数にformula()関数を噛ませたcharacter型(文字列)として与えることで,文字列のまま正しく機能させることが出来ます。
ということで,先程のコードを更に書き換えていきます。
formula()関数を使って修正
# 列をdat$の代わりにchr型で指定する
# 1. 合計点で10個にグルーピングしたものをdatに追加する
dat$group <- cut2(dat[, total], g = 10, levels.mean = TRUE)
# 2.1 formulaの文字列を作る
fml <- paste0(x, " ~ group")
# 2.2 ある項目について,グループ平均値を出す
group_mean <- aggregate(formula(fml), dat, mean, na.rm = TRUE)
# 3.1 factor型になっているところをnumericまたはinteger型に修正する
group_mean$group <- as.numeric(as.character(group_mean$group))
# 3.2 プロットする
plot(group_mean, type = "b")これでようやく完成です。 うまくできていれば, 図 4.21 と同じトレースラインができるはずです。
最後に,「変わる部分」を引数として,このコードをまるごと関数に入れてしまいましょう。 コメントは残しておくとあとあと見返したときにわかりやすいのでおすすめです。
traceline <- function(x, total) {
# 1. 合計点で10個にグルーピングしたものをdatに追加する
dat$group <- cut2(dat[, total], g = 10, levels.mean = TRUE)
# 2.1 formulaの文字列を作る
fml <- paste0(x, " ~ group")
# 2.2 ある項目について,グループ平均値を出す
group_mean <- aggregate(formula(fml), dat, mean, na.rm = TRUE)
# 3.1 factor型になっているところをnumericまたはinteger型に修正する
group_mean$group <- as.numeric(as.character(group_mean$group))
# 3.2 プロットする
plot(group_mean, type = "b")
}
関数化する必要があるのは,トレースラインの作成のように,同じような処理を繰り返す必要がある場合です。 同じ処理を何度も書いてしまうと,あとから修正を加えた際に一部だけ修正して,残りを修正し忘れる,といって面倒が発生してしまいます。 コードの保守や可読性の観点から,同じような処理はなるべく繰り返し記述しないようにすることが望ましいわけです。 このルールは,プログラミングの世界では,よくDRY(Don’t Repeat Yourself)原則と呼ばれたりしています。
ということで,関数化の手順をまとめると,以下のようになります。
- まずは愚直にコードを書く
- 繰り返しにおいて変わる場所を変数に置き換える
- うまく動くように必要に応じてコードを修正する
function()関数を使って関数を作成する
特に3. の部分に関しては,毎回どのようなエラーが発生するかは分かりません。 したがって,Rの経験値が重要になってきます。 同じ結果をもたらす処理の書き方が複数通り存在するということを知っていることで,解決策が見いだせるかもしれないのです(traceline()の例の場合,データフレームの列名指定は$ではなくcharacter型を使った方法の可能であることや,formulaの指定時にcharacter型にformula()を噛ませる方法もあるいうこと)。
【おまけ2】選択肢ごとのトレースライン
一応,以下に「選択肢ごとの選択率のトレースライン」のコード例を載せておきます15。ただこれは,多肢選択形式の(つまり誤答選択肢の間には順序関係が無い)問題について誤答選択肢を分析するような場合には有効ですが,心理尺度の項目分析の場合はここまでやらなくても良いかもしれません。
# 今回は10群に分けてやってみる
group_A <- cut2(dat[, "Q1_A"], g = 10, levels.mean = TRUE)
# グループごとに合計点の平均値を出す(X軸用)
group_mean <- aggregate(Q1_A ~ group_A, dat, mean, na.rm = TRUE)
# 各選択肢のグループごとの選択率を出すために関数を作る
# ↓ベクトルの中で値がkの割合を計算する関数
prop_k <- function(vec, k) {
mean(vec == k)
}
# 選択肢1のグループごとの選択率を出す
# 一時的な(無名)関数の定義を利用する
group_prop1_item <- aggregate(Q1_3 ~ group_A, dat, prop_k, 1)
# 他の選択肢についても
group_prop2_item <- aggregate(Q1_3 ~ group_A, dat, prop_k, 2)
group_prop3_item <- aggregate(Q1_3 ~ group_A, dat, prop_k, 3)
group_prop4_item <- aggregate(Q1_3 ~ group_A, dat, prop_k, 4)
group_prop5_item <- aggregate(Q1_3 ~ group_A, dat, prop_k, 5)
group_prop6_item <- aggregate(Q1_3 ~ group_A, dat, prop_k, 6)
# X軸はグループごとの「合計点」の平均値
# Y軸は各選択肢のグループごとの選択率
# type="n"とすると,何も表示しない=枠だけ作る
plot(
x = c(min(group_mean$Q1_A), max(group_mean$Q1_A)),
y = c(0, 1),
type = "n",
xlab = "グループ平均値",
ylab = "選択率"
)
# 選択肢ごとに線と点を別々に描き足していく
# 選択肢1
lines(x = group_mean$Q1_A, y = group_prop1_item$Q1_3) # 線
points(x = group_mean$Q1_A, y = group_prop1_item$Q1_3, pch = "1") # 点
# 選択肢2
lines(x = group_mean$Q1_A, y = group_prop2_item$Q1_3) # 線
points(x = group_mean$Q1_A, y = group_prop2_item$Q1_3, pch = "2") # 点
# 選択肢3
lines(x = group_mean$Q1_A, y = group_prop3_item$Q1_3) # 線
points(x = group_mean$Q1_A, y = group_prop3_item$Q1_3, pch = "3") # 点
# 選択肢4
lines(x = group_mean$Q1_A, y = group_prop4_item$Q1_3) # 線
points(x = group_mean$Q1_A, y = group_prop4_item$Q1_3, pch = "4") # 点
# 選択肢5
lines(x = group_mean$Q1_A, y = group_prop5_item$Q1_3) # 線
points(x = group_mean$Q1_A, y = group_prop5_item$Q1_3, pch = "5") # 点
# 選択肢6
lines(x = group_mean$Q1_A, y = group_prop6_item$Q1_3) # 線
points(x = group_mean$Q1_A, y = group_prop6_item$Q1_3, pch = "6") # 点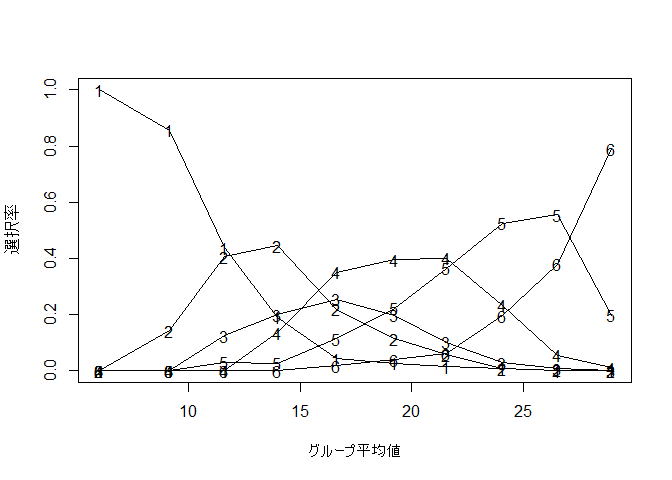
Q1_3)
心理尺度項目では,各選択肢は順序変数になっています。ということは良い項目の場合, 図 4.23 のように,各選択肢のピークが順番に並ぶはずです。もしもX軸の値に関係なく「どちらでもない」の選択率が高い,といった事があれば,その項目では潜在特性以外の何かしらの理由で「どちらでもない」を選択している人が一定数いそうだ,ということを確認したりはできると思います。
学力テストの場合は,ふつう選択肢に順序関係はありません。したがって,「どの選択肢が誤答として良く働いているか」や「下位層が特に引っかかりやすい誤答選択肢がないか」など,選択肢レベルでの詳細な検討を行うことが出来るわけです。
4.4 信頼性と妥当性の考え方
デジタル体重計を開発する場合には,必ず出荷前に品質チェックを行うでしょう。その内容はきっと「10kgのおもりを載せた時にきちんと10kgと表示するか」や「様々な環境下で測定しても安定して同じ重さを表示できるか」といったものだと推測されます。
これと同じように心理尺度の開発においても品質チェックが重要になります。構成概念という目に見えないものを測定しようとする心理尺度の場合,そのチェックは難解を極めます。例えば「10kgのおもり」のように客観的にみて正しいと証明されている基準がないことや,通常複数の項目の集合で単一の構成概念を測定すること,測定の安定性を脅かす要因が多様であることなどがあるために,完全な形での品質チェックはほぼ不可能と言っても過言ではありません。
測定の質は,大きく分けると妥当性(validity)と信頼性(reliability)という2つの概念のもとで議論されます。 簡単に言うと,妥当性は「測定値が,測定しようとしている構成概念を正しく表した値か」の程度です。例えば「デジタル体重計」という名前で身長を測定する機械があったとすると,これは明らかに妥当性がありません。さすがに体重計と身長計を間違えることは無いでしょうが,心理尺度の場合,なにせ構成概念が目に見えないので,「外向性」のつもりで作った尺度が実は「攻撃性」を測定していた,ということが起こる可能性はゼロとは言えないのです。
一方,信頼性は「測定値が,一貫して同じ値を表しているか」の程度です。例えば同じ人なのに乗るたびに表示される値が変わる体重計や,同じメーカーの同じ型番の体重計なのに物によって表示される値が変わる体重計があっても,その結果を信頼することは出来ません。心理尺度でも同じことが言えます。
妥当性と信頼性は完全に独立した概念ではありません。これらの関係性は,よく 図 4.24 のようなダーツのアナロジーによって説明されます。赤いマル一つ一つがダーツの刺さった場所を表していると考えてください。ダーツ本来の目的である「真ん中に当てる」ということが,心理尺度でいう「測定しようとしている構成概念を測定する」に相当します。真ん中に近いほど測定しようとしているものに近い,ということですね。

図 4.24 の一番左は,信頼性も妥当性も低いパターンです。毎回あっちへ行ったりこっちへ行ったりで,測定が全く安定していません。毎回ぜんぜん違う結果が出てくるので,特定の回で見ればたまたま測定したい真の値に近い結果が出ることもあるかもしれませんが,結局いつ当たったかがわからない以上使い物にはならないでしょう。
図 4.24 の真ん中は,信頼性は高いが妥当性は低いパターンです。「デジタル体重計」という名前で身長を測定する機械があれば,これに該当するでしょう。毎回ほぼ同じ値を返してくるが,毎回「測定しようとしているもの」とは異なる値を返している,という状態です。この場合は,元々想定していた名前の尺度としては使えないかもしれませんが,もしこの尺度が本当は何を測定していたかがわかれば,(マト自体をうごかしてやることで)別の尺度としては使えるようになるかもしれません。
図 4.24 の一番右は,信頼性も妥当性も高いパターンです。この状態に持っていくことができれば,いつどこで測定しても安定して「測定しようとしている構成概念」を測定できるため,安心して心理尺度を利用することが出来ますね。
ということで,心理尺度を作成・利用する際には,信頼性も妥当性も高くないといけないということがわかりました。また,ダーツのアナロジーからは信頼性は妥当性の必要条件だということがわかります。つまり「妥当性が高いのに信頼性が低い」というケースはあり得ない,ということです。
また,妥当性・信頼性を考える際に注意しなければいけないのは,妥当性・信頼性は尺度自体が持つ固有の性質ではなく,尺度得点に関する性質として随時評価されるという点です (Streiner & Norman, 2008)。 付録 A では,心理尺度が翻訳や時代の変化によって変質してしまう危険性を指摘しました。 つまり,ある集団において「良い」と判断された尺度があったとしても,それが自分の集めたサンプルについても「良い」尺度であるかどうかはわからない,ということです。 したがって,先行研究ですでに妥当性や信頼性が検証済みの尺度を利用する場合でも,基本的には自分で集めたデータにおける妥当性・信頼性は改めて評価する必要があると言えるでしょう。 もちろん,先行研究で検証に使用されたサンプルの母集団と,自分が利用するデータの母集団が(測定したい内容に関して)概ね同じであることが示せるならばいちいち再評価する必要はありません。 まとめると,どこかから尺度を探して利用する場合には,妥当性・信頼性は改めて評価する必要があるかよく考える必要があるということです。
それでは,ここからは具体的に妥当性・信頼性を検証するための方法について見ていきましょう。
4.5 妥当性の検証
妥当性の考え方は,未だにちょくちょく変化しています。 その歴史的な変遷については例えば 村山 (2012) や Streiner & Norman (2008) などが詳しいですが,妥当性の考え方自体にトレンドのようなものがあり,「これぞ」という万人が納得できる答えはまだ見つかっていません。 そしてこのあたりの話には科学哲学も入り込んでくるかなり複雑な話になるため,ここでは深く取り上げないことにして,まずは現代の妥当性の主流となっていると思われる Messick (1995) の考え方を紹介します16。
4.5.1 妥当性の考え方
もともと心理学界隈では,妥当性にはいくつかのタイプが存在すると考えられていました (村山,2012)。
1つ目は基準連関妥当性 (Criterion-related Validity)です。 これは,ある尺度によって測定された得点が,すでにその効果を認められている外的な基準とどの程度相関しているかによって評価されます。 何かを測定するための方法が確立しているが測定自体が大変(お金や時間がかかる,などの)ときに,それよりも簡便な方法で同じものが測定できたら嬉しい,という考えが背景にあります。例えば認知症の診断を行う場合には,MRIを撮って脳の萎縮度を見ればほぼ確実な診断ができますが,これには相当なお金がかかってしまいます。 もしもこれが,認知機能を測るいくつかの質問項目でほぼ同等の診断ができるとしたら,とても嬉しいわけです。 つまり,基準連関妥当性では,尺度を別の測定の代理変数 (proxy) として考えている節がありそうです。
2つ目は構成概念妥当性 (Construct Validity)です。 基準連関妥当性の考え方と比べると,構成概念妥当性では,ある尺度によって測定された得点を,その背後にある構成概念の顕在化した指標という感じで考えます。 そして,構成概念の世界において理論的に導出される仮説に合致する結果が得られた場合に,「確かにその尺度は想定していた構成概念を測定する尺度なんだ」と言えるわけです。 例えば「きょうだいの数」が多いほど大人になったときの「外向性」が高い,というナントカ理論が存在したとします。 このとき,「外向性」を測定するために作成した(がまだ本当に外向性を測定できているかわからない)尺度の得点と「きょうだいの数」に強い正の相関が見られたとしたら,この尺度はたしかに「外向性」を測定出来ている気がしてきます。 もちろん,このたった一つの結果だけで尺度の妥当性が示せるわけではないですが,このような要領で,構成概念の世界において理論的に導出される様々な仮説を一つ一つ検証していくことで,その尺度が「もともと測定したかったもの」を表している可能性が高められていくわけです。 俗に「収束的妥当性 (Convergent validity)」や「弁別的妥当性 (Discriminant validity)」と呼ばれるものは,「相関が高い(低い)構成概念の間では,それらを測定する尺度同士の得点も相関が高い(低い)はず」という構成概念妥当性の考え方にもとづいたものです。
3つ目は内容的妥当性 (Content Validity)です。 これは,構成概念妥当性と同様に,ある尺度は特定の構成概念を測定するためのものとして考えます。 ですが,内容的妥当性では「他の構成概念との関係」などではなく,その尺度自体の内容から妥当性を判断します。 具体的には尺度の項目セットが,構成概念が指し示すあらゆる現象の全体からまんべんなく・過不足なくサンプリングされたものであれば「内容的妥当性が高い」と判断することが出来ます。 例えば「高校数学の理解度」を評価するための(大学入試の)数学のテストでひたすら連立方程式問題ばかりが出題されたとしたら,これは「高校数学の理解度」と言うよりは「連立方程式の理解度」になってしまいます。 このような場合には,内容的妥当性が低いと判断されてしまうわけです。
以上のように,妥当性には基準連関妥当性,構成概念妥当性,内容的妥当性の3つのタイプがある,と長らく考えられてきました。 しかしこの考え方は一方で「この3つの妥当性をそれぞれクリアしたら良いんだな」というように,妥当性検証のプロセスをスタンプラリー化してしまった (Landy, 1986)といった批判を生み出してしまいます。
こうした批判を踏まえて Messick (1995) は,妥当性とは「構成概念妥当性」そのものであるという主張をしました。 つまり妥当性を「尺度得点の意味や解釈に関する様々な証拠を統合したもの」と定義したわけです。 ここで重要なのは,妥当性が尺度得点をつかって行う解釈や推論がどれだけ信頼できるものかを表すための指標として考えられている点です。 そしてこの定義に従うと,基準連関妥当性や内容的妥当性はいずれも,(構成概念)妥当性を示す傍証の一つとして考えることが出来ます。 その意味で,これらは妥当性の「基準連関的証拠」や「内容的証拠」と呼ばれることがあります。
Messickの考え方では,妥当性の証拠としてどのようなものが重要視されるかは,尺度の目的などによって変わります。 例えば「同じ構成概念を少ない項目数で測定したい」という短縮版尺度の目的からすると,元の尺度との相関によって示される「基準連関的証拠」が重要になるでしょう。 一方で,学力テストのように総合的な能力を評価したい尺度では,専門家などによって内容的側面の評価が重要になるはずです。 このように,本来妥当性の評価は「お決まりのパターン」があるわけではなく,目的と対象に応じて必要な証拠を収集していく作業です17。
といった議論を踏まえて,ここからはアメリカ心理学会が発行している「テストスタンダード18」 (2011)に掲載されている妥当性の証拠のパターンについて紹介したいと思います。
内容について
内容に関する証拠(Evidence based on test content,内容的妥当性とも呼ばれる)は,データから確認するというよりも,尺度作成時の手続きに関する話です。構成概念および下位概念の定義を明確にした上で,その定義を満たすと考えられる内容に関する項目をきちんと用意する必要があり,その手続きに関して論文などの中での説明が求められます。いわゆる「複数の専門家によって議論した」であったり,項目案を先行研究から引用したり,という話は,この点をクリアするために必要な記述,というわけですね。
具体例としては,例えば「外向性」を測定するための尺度を作成する場合には,「外向的な人がよくやる一方で内向的な人はあまりやらないこと」のような行動や考え方を項目として用意すると良さそうです。 そのような項目を用意することができれば,「その尺度の得点が高い」ということを「外向性が高い」と解釈することは妥当だと言えるでしょう。 同様に,ある病気の診断尺度であれば,その病気の典型的な症状を項目として用意することができれば,「その尺度の得点が高い」ということを「その病気にかかっている」と解釈することはやはり妥当だと言える気がしてきます。
認知的なこと
回答過程に関する証拠(Evidence based on response processes)は,回答者が各項目に対して,作成者の想定していた通りに「測定しようとしている構成概念」のことを考えていたか,といった側面のことです。テストスタンダード内でもこの点に関する記述はかなり少なく,また実際の論文などでこの側面に関して妥当性検証を行っているものは見たことが無い(かなり少ない?)のですが,検証する方法としてCognitive interview (e.g., Beatty & Willis, 2007; Peterson et al., 2017)といった方法があるようです。例えば「回答中に,(構成概念)についてどのようなことを考えていましたか?」と言った内容を事後的にインタビューする方法のようです。かなり大変そうですね…
内部構造
内部構造に関する証拠(Evidence based on internal structure,因子妥当性とも呼ばれる)は,いわゆる「因子構造」のことを指していると思われます。事前に因子の構造(下位概念)について仮定を置いて項目を作成した場合には,因子分析をした結果,項目が想定通りの分かれ方をしていれば良さそうな気がする,ということです。 この視点に関連する分析(因子分析)の結果を「妥当性の証拠」という位置づけで提示する研究は心理学ではあまり見られないですが,マーケティング系などでは割と用いられている気もします19。 「構成概念をこう定義して,下位概念としてこれとこれがあると考える」という仮定のもとで,項目が実際に下位概念と適合する形で分かれるようであれば,妥当性の傍証にはなりそうです20。
また,もしも特定の属性の人では異なる挙動を示す項目(特異項目機能: DIF, Differential Item Functioning)や尺度があったとすると,これは妥当性を脅かす要因の一つになりえます。 DIFの対象となりうる属性の例としては,年齢や性別,人種や宗教など様々なものが考えられます。 DIFが発生しそうな項目の例も挙げておきましょう。例えば「他者に助けを求める傾向」という尺度の中に「苦しいときには神に祈る」という項目があったとします。項目作成者としては「他者に助けを求める傾向が強いほど,神にもすがるようになるだろう」という感覚で項目を作成したとしても,実際にはたぶん宗教観によってその回答は大きく変わるでしょう。 本来,尺度項目への回答は想定される構成概念(因子)の強さのみによって規定されるべきですが,DIFがある場合にはこれに加えて特定の属性が影響を与えていると考えられます。すなわち,その特定の属性が意図していなかった因子として因子構造に混ざってしまっている,という状態です。先程の例で言えば,その項目だけが「他者に助けを求める傾向」と「宗教観」という2つの因子の影響を受けてしまっている,ということになり,これは当初想定していた因子構造から逸脱してしまっている状態です。 こういったことがないかを確認するために,分析の際にはデータを属性ごとに分割してそれぞれで分析を行ったり,SEMの枠組みの中で多母集団同時分析を行ったりするわけですね。
他の変数との関係
他の変数との関係に関する証拠(Evidence based on relations to other variables,基準連関妥当性とも呼ばれる)は,たぶん妥当性検証の中では最もよく提示される証拠です。概念的に関連があると考えられる別の尺度や指標との相関が高いこと(収束的証拠)や,概念的に関連がないと考えられるものとの相関が低いこと(弁別的証拠)をもって,妥当性の証拠とします。
先程説明した通り,比較対象の変数は,心理尺度に限りません。例えば「外向性」の妥当性検証であれば,「SNSの友だちの数」や「直近1年で何回パーティーに行ったか」といった行動指標なども考えられるでしょう。 むしろ心理尺度どうしの相関では,両方の変数の誤差項には共通の「自己申告によるバイアス」が含まれることで,誤差項同士が相関してしまう可能性があります。その結果,本当の相関よりも過大に推定されてしまうかもしれません(common method bias, Podsakoff et al., 2003)。そういった意味で,心理尺度以外の変数(特に行動指標)との関連を考えてみるのも良いでしょう。
また,「予測」という観点でもこの妥当性は重要な意味を持ちます(予測的妥当性)。例えば入社試験での性格検査は,「外向的な性格のひとだから営業に配属しよう」的な意思決定を行うために利用されているかもしれません。言い換えると,この性格検査には,最もパフォーマンスが良くなる配属先を予測する機能が求められていることになります。この場合,性格検査が「測定しようとしている構成概念を測定できている」ことよりも,「それによって将来のパフォーマンスが予測できている」ことのほうが重要になります。 この場合,やることとしては尺度得点と「1年後の営業成績」の相関を見るということで,やることは先程と同じですが妥当性の観点は異なっていたりします。
4.5.2 まとめ
妥当性を検証する最良の方法,というものは見つかっていません。というか多分一つに決めるのは不可能です。 したがって,上に紹介したような妥当性検証の方法についても,お決まりのルーティーン実行したら十分(スタンプラリー)というわけではなく,可能であれば複数の観点から検証した上で「これだけ証拠が出揃ってるんだからいいだろう」的なスタンスで行くことが望ましいですね。
また,上記の例からも分かるように妥当性の検証は,基本的には検証対象の尺度への回答データのみでは十分には行えないと思っておく必要があります。例えば「他の変数との関係に関する証拠」を集めるためには,検証対象の尺度への回答データに加えて,関連する別の尺度への回答データや行動指標が必要になります。 またDIFの有無を検証する場合には,DIFを引き起こす可能性のある属性についてのデータも必要になります。 このように,妥当性の検証には様々なデータが必要になることが多いので,例えば尺度を作成する場合など,本気で妥当性を評価しようとするならば,必要なデータを調査設計の時点ですでに考えておく必要があるのです。
4.6 信頼性の検証
信頼性は,妥当性よりは統計的に評価することが出来ます。そのために,古典的テスト理論 (Classical Test Theory [CTT]: Lord & Novick, 1968)に基づく以下のモデルを考えます。
\[ x = t + e \tag{4.1}\] (4.1)式において,\(x\)は実際に観測される得点を,\(e\)は測定誤差を表します。そして\(t\)は真値と呼ばれます。言い換えると\(t\)こそが「測定しようとしている構成概念」を直接的に反映した値である,ということです。理想的には,真値\(t\)のみによって回答値が決まれば良いのですが,それに対して何らかの測定誤差が混ざることで,実際に観測される得点が決まる,という状況を仮定しています。
このモデルにおける重要な(そして自然に受け入れられる)仮定として,真値と測定誤差は無相関ということが置かれます。したがって,観測値\(x\)の分散は \[ \sigma^2_x = \sigma^2_t + \sigma^2_e \tag{4.2}\] というように,真値と測定誤差の分散の単純な和として表すことができます。このとき,信頼性係数\(\rho\)は \[ \rho=\frac{\sigma^2_t}{\sigma^2_x}=1-\frac{\sigma^2_e}{\sigma^2_x} \tag{4.3}\] と表すことができます。つまり,観測変数の分散に占める真値の分散の割合ということです。もちろん実際に知ることができるのは観測値の分散\(\sigma^2_x\)だけであり,真値の分散\(\sigma^2_t\)を知ることはできません。
以下で紹介する信頼性係数の求め方は,このような仮定のもとで,信頼性係数\(\rho\)を直接求めようとしています。いくつかの方法があるのですが,測定誤差として何を取り上げているかが方法によって異なるので,その点には少し注意が必要です。なお,ここから先の説明については 岡田 (2015) を拝借しています。
4.2 式の要領で妥当性を定式化する方法も一応存在しています。 CTTでは,観測得点を「真値」と「誤差」に分解していましたが,このうち「誤差」をより詳細に見ていくと,「系統誤差 (systematic error)」と「偶然誤差 (random error)」に分けることが出来ます (Maruyama & Ryan, 2014)。
系統誤差とは,繰り返し測定を行った場合に測定値を常に一定方向に動かすような誤差です。例えば体重計が壊れていて常に実際の体重よりも5%大きな値を表示してしまう場合を考えてみます。 この体重計では,同じ人が何回乗っても必ず実際の体重より少し大きな値が出てしまっているわけなので,これは系統誤差にあたります。
一方偶然誤差とは,繰り返し測定を行った場合に測定値が毎回ランダムに変動してしまうような誤差です。 体重計で言えば,「乗るたびに表示される値が変わる」程度を指しています。
ポイントは,真値と偶然誤差が無相関であるように,系統誤差と偶然誤差も無相関であるという点です。 これを踏まえると観測値の分散は,系統誤差による分散\(\sigma^2_{SE}\)と偶然誤差による分散\(\sigma^2_{RE}\)を用いて(4.2)式からさらに以下のように分解することが出来ます。 \[ \begin{aligned} \sigma^2_x &= \sigma^2_t + \sigma^2_e \\ &=\sigma^2_t + \sigma^2_{SE} + \sigma^2_{RE} \end{aligned} \]
ここで信頼性の定義に立ち返ってみると,信頼性とは「測定値が,一貫して同じ値を表しているか」の程度でした。 この観点から言うと,常に同じだけ値をずらす系統誤差は信頼性に影響がないことがわかります。 したがって,信頼性は \[ \rho=\frac{\sigma^2_t + \sigma^2_{SE}}{\sigma^2_x}=1-\frac{\sigma^2_{RE}}{\sigma^2_x} \] と表すことが出来ます。 一方で,妥当性は「測定値が,測定しようとしている構成概念を正しく表した値か」の程度なので,系統誤差であってもそのズレは許容されません。 したがって,妥当性は \[ \rho=\frac{\sigma^2_t}{\sigma^2_x}=1-\frac{\sigma^2_{SE} + \sigma^2_{RE}}{\sigma^2_x} \] と表すことができるわけです。
4.3式では,信頼性を観測変数の分散に占める真値の分散の割合として表しました。 しかし実際には真値と系統誤差は区別できないことが多いのです。 例えば体重の真値がわからないときに,ある体重計が「乗るたびに値が変わる」ことはわかっても,「常に5%大きな値を示している」ことを証明するのはかなり難しいでしょう。 なのですが,信頼性の定義からすると,系統誤差の有無は実用上問題ではありません。 そのため,この後紹介する信頼性の評価方法においても,系統誤差は無視して扱っています。
4.6.1 (平行テスト法)
はじめに,真の信頼性係数\(\rho\)を求めるための「理想」のお話を少しだけしておきます。 真の信頼性係数\(\rho\)を求めるためには,真値と誤差分散が同じ2つのテスト(平行テストと呼ぶ)を独立に実施する必要があります。 平行テストがある場合,2つのテスト得点\(x_1\)および\(x_2\)はそれぞれ \[ \begin{aligned} \begin{split} x_1 &= t + e_1 \\ x_2 &= t + e_2 \end{split} \end{aligned} \tag{4.4}\] と置くことが出来ます。この2つのテスト得点の共分散\(\sigma_{x_1x_2}\)は,真値と測定誤差は無相関であり,また独立に実施しているならば異なるテストの真値と測定誤差も無相関(\(\sigma_{t,e_2}=\sigma_{e_1,t}=\sigma_{e_1,e_2}=0\))になるはずなので, \[ \begin{aligned} \begin{split} \sigma_{x_1,x_2} &= \sigma_{(t+e_1),(t+e_2)} \\ &= \sigma_{t,t} + \sigma_{t,e_2} + \sigma_{e_1,t} + \sigma_{e_1,e_2} \\ &= \sigma_t^2 \end{split} \end{aligned} \tag{4.5}\]
となり,結果的に真値の分散に一致します。また,誤差分散が同じであれば,2つのテストの得点の分散は一致する(\(\sigma^2_{x_1}=\sigma^2_{x_2}=\sigma^2_x\))ため,真の信頼性\(\rho\)は \[ \begin{aligned} \begin{split} \rho &= \frac{\sigma^2_t}{\sigma^2_x} \\ &= \frac{\sigma_{x_1,x_2}}{\sigma_{x_1}\sigma_{x_2}} \\ &= r_{x_1,x_2} \end{split} \end{aligned} \tag{4.6}\] ということで,2つのテスト得点の相関係数に一致するため,理論上は計算可能となるわけです。
4.6.2 再テスト法
ただ,真値と誤差分散が同じ2つのテスト・心理尺度なんていうものは,言い換えると内容は異なるが平均点および分散が全く同じテスト・尺度ということであり,そう簡単には作れません。そこで,同じテスト・尺度を2回実施するという考えが浮かんできます。これならば,当然内容は全く同じなので平行テスト法の条件は満たされているといえます。
心理尺度の場合,この再テスト法でもそれなりに妥当に信頼性を測定できるような気がします。しいて言えば,2回間隔をあけて同じ人に実施することのコストがかかりますが,それさえクリアできれば…という感じです。
学力テストの場合,同じ問題のテストを2回実施するのはほぼ不可能です。出題がネタバレしているテストならば,事前準備が容易なため2回目の方がほぼ確実に得点が高くなってしまうでしょう。ということで再テスト法もできそうにない,ときました。さてどうしようか…
4.6.3 折半法
1回のテストで平行テストみたいなものを2つ用意するために,大昔には1つのテストを2つに分けるという考え方が用いられていました。1つの尺度ならば,うまいこと半分に分ければ平行テストに見えなくもない気がします。この折半法では,2つに分けたときのそれぞれの得点の相関\(r_{x_1,x_2}\)について,スピアマン・ブラウンの公式にもとづいて,信頼性を \[ \rho_{sh} = \frac{2r_{x_1,x_2}}{1+r_{x_1,x_2}} \tag{4.7}\] と計算します。
平行テスト法および再テスト法では,真値\(t\)は尺度全体の真値を,誤差分散\(e\)には尺度の外側にある余計なものを想定していました。これに対して折半法での信頼性は,真値\(t\)は尺度の半分の真値(尺度の中で共通の成分)を,誤差分散\(e\)には尺度の中の項目間(前半と後半)で異なる成分を表している,と見ることが出来ます21。その意味では真の信頼性\(\rho\)とはちょっと意味合いが異なるのですが,ひとまず折半法によって,1回のテストから信頼性係数が求められるようになった,ということでこの方法が一時期スタンダードだったわけです。 ちなみに,折半法的な意味での信頼性は内的一貫(整合)性などと呼ばれたりします。
ただ,当然ですが折半法では尺度の分け方によって信頼性係数の値が変わってしまいます。これはScienceとしてはあまりよろしくないですね。特に現代のコンピュータを使えば,全ての分け方を試した上で最も高い値を示す分け方で信頼性を主張してしまうことも可能でしょう。これは良くないということで,折半のやり方に依存せず一意に値が決まる信頼性係数として,尺度内のすべての項目の分散や共分散を用いたKR-20 (Kuder & Richardson, 1937) と呼ばれる公式22が提案されました。これならば分け方の恣意性は無視できるようになります。ただしKR-20は二値項目にしか適用できない公式だったため,このままではリッカート式の尺度などには使えません。
4.6.4 クロンバックの\(α\)係数
現在最も広く用いられている\(\alpha\)係数 (Cronbach, 1951) は,KR-20を多値項目でも使えるようにクロンバックが一般化したものです。\(n\)項目の尺度に対する\(\alpha\)係数の計算式は \[ \alpha=\frac{n}{n-1}\left(1-\frac{\sum_{i=1}^{n}\sigma_{x_i}^2}{\sigma^2_{x}}\right) \tag{4.8}\] と定義されています。
\(\alpha\)係数は今でも様々な論文で利用されているものですが,様々な批判もあります。
- \(\rho\)の下界の一つであるため,ほぼ確実に\(\rho\)を過小推定する23
- 項目数が多いほど大きな値になりやすい=項目数の影響を受ける
- 一次元性の指標とはいえない側面がある
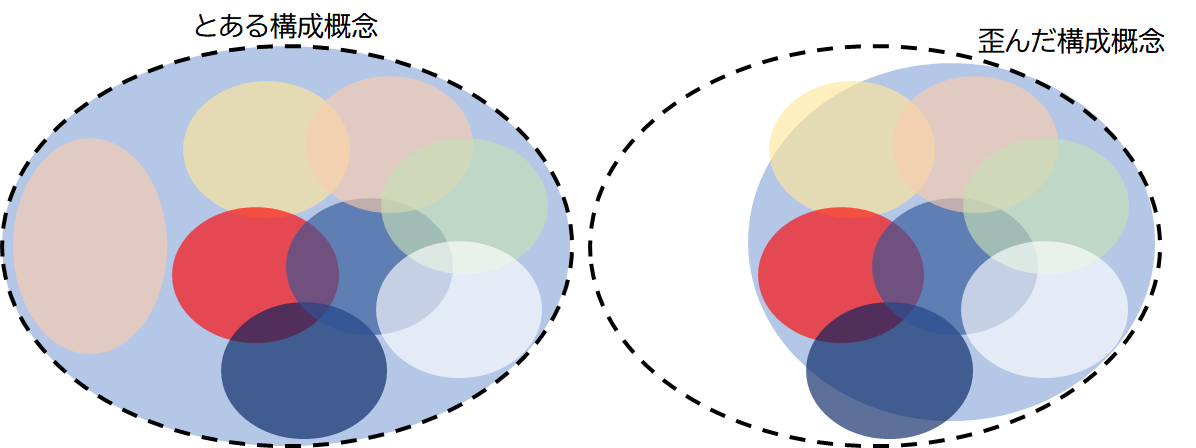
3点目については, 図 4.25 にあるように,実際には尺度が一次元ではなさそうな場合でも,\(\alpha\)係数だけを見ていては判断できないケースがある,ということです。 現在でも多くの論文が\(\alpha\)係数だけを見て「一次元性が確認された」などと供述していますが,実際には\(\alpha\)係数は一次元性の必要条件にすぎず,もうすこし詳細な確認をすべきだと言えます。

そんな\(\alpha\)係数に変わって,現在では\(\omega\)係数などの信頼性係数や,SEMに基づく方法,一般化可能性理論と呼ばれる理論に基づく方法が提案されています。ただここで説明している余裕と事前知識が不足しているため,後ほど因子分析の回において\(\omega\)係数を紹介します。
とはいえ\(\alpha\)係数はまだ現役で使われている方法なので,ここでも\(\alpha\)係数の使い方を紹介しておきます。Rではpsych::alpha()という関数があります。今回のように一因子ではなく複数の因子がある尺度の場合は,25項目全てではなく各因子ごとにalpha()関数を適用し,それぞれで出た値を報告するようにしましょう。
Reliability analysis
Call: alpha(x = dat[, paste0("Q1_", 1:5)])
raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
0.71 0.72 0.69 0.34 2.6 0.0092 4.6 0.91 0.35
95% confidence boundaries
lower alpha upper
Feldt 0.7 0.71 0.73
Duhachek 0.7 0.71 0.73
Reliability if an item is dropped:
raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
Q1_1 0.73 0.74 0.68 0.41 2.8 0.009 0.0061 0.39
Q1_2 0.63 0.64 0.59 0.31 1.8 0.012 0.0167 0.30
Q1_3 0.61 0.63 0.57 0.30 1.7 0.013 0.0089 0.34
Q1_4 0.69 0.70 0.66 0.37 2.4 0.010 0.0155 0.37
Q1_5 0.66 0.67 0.62 0.34 2.0 0.011 0.0126 0.35
Item statistics
n raw.r std.r r.cor r.drop mean sd
Q1_1 2432 0.59 0.58 0.39 0.32 4.6 1.4
Q1_2 2432 0.73 0.75 0.67 0.57 4.8 1.2
Q1_3 2432 0.77 0.77 0.72 0.60 4.6 1.3
Q1_4 2432 0.67 0.64 0.49 0.41 4.7 1.5
Q1_5 2432 0.69 0.70 0.60 0.50 4.5 1.3
Non missing response frequency for each item
1 2 3 4 5 6 miss
Q1_1 0.03 0.08 0.12 0.14 0.30 0.33 0
Q1_2 0.02 0.05 0.06 0.20 0.37 0.32 0
Q1_3 0.03 0.06 0.07 0.20 0.36 0.27 0
Q1_4 0.05 0.08 0.06 0.16 0.24 0.41 0
Q1_5 0.02 0.07 0.09 0.22 0.35 0.25 0出力を上から見ていきましょう。
2-6行目 (Reliability analysis)
各種信頼性係数の指標です。基本的には最初の2つのalphaを見ておけばOKです。
raw_alpha- データの共分散行列から普通に計算した\(\alpha\)係数です。本来的な定義( 4.8式)はこれなので,基本的にはこれを報告しておけばOKです。
std.alpha-
共分散行列の代わりに相関行列を用いて計算した\(\alpha\)係数です。例えば特に項目ごとに最大値・最小値が一定ではないような場合,取りうる値の幅が大きい項目のほうが分散も大きくなるため,\(\alpha\)係数にかかる重みが極端に大きくなってしまいます。 このような場合には,項目の重みを揃えるため,相関行列を用いたこちらの\(\alpha\)係数を報告するほうが良いかもしれません。 ただしリッカート尺度の場合はふつう最小値・最大値は同じなので,
raw_alphaと極端に異なるケースは,天井・床効果が発生している場合を除けばほぼ無いと思います。
気になる人もいるかもしれないので解説しておきます。左から
G6(SMC)- 俗にガットマンの\(\lambda_6\) (Guttman, 1945) と呼ばれる指標です。各項目について「それ以外の項目で重回帰分析した際の重相関係数」をもとに計算する指標です。重相関係数が高いということは,その項目が「他の項目との相関が高い」ことを意味するため,これも内的一貫性の指標になっています。が,\(\alpha\)係数を報告しておけば十分です。
average_r- 項目間相関の平均値です。5項目ならば\({}_5C_2=10\)通りの相関があり,その平均値です。
s/n-
Signal/Noise比です。上の
average_rを\(r\)とすると,\(nr/(1-r)\)で計算されています。 ase- \(\alpha\)係数の漸近標準誤差(asymptotic standard error)だと思われます。
mean- 項目レベルでの平均値です。
sd- 項目レベルでの標準偏差です。
median_r- 項目間相関の中央値です。
8-11行目 (95% confidence boundaries)
raw_alphaの95%信頼区間です。どちらの方法でも別にかまわないですが,余裕があればいずれかの信頼区間を報告するようにしましょう。
13-19行目(Reliability if an item is dropped)
1項目を除外した時に各種指標がどう変化するかを表しています。今回の場合,raw_alphaを見るとQ1_1だけは5行目に表示されているものよりも高い値を示しています。つまりこの場合,統計的にはQ1_1は除外したほうが内的一貫性は高まる,ということです。 ただ,実際にはこれを見て機械的に項目を除外するのではなく,内容面などを吟味した上で削除するかを決定しましょう。 図 4.26 のように,特定の項目が他の項目と相関が低いとしても,内容的にその項目が無いと構成概念の全要素をカバーしているとは言えなくなるような項目であれば,除外せず残したほうが妥当性は高い可能性があります24。 今回の場合は,raw_alphaも大した改善ではないので,このまま残して分析を進めることにします。
21行目以降(Item statisticsおよびNon missing response frequency for each item)
項目ごとの要約統計量および各カテゴリの選択率です。まあ,説明することも無いでしょう。ちなみに,23-27行目の一番左のraw.rはピアソンの積率相関係数として計算した場合のI-T相関を指しています。
4.6.5 信頼性係数の基準
信頼性係数は,その定義から\(0\leq\rho\leq1\)の値を取ります。直感的には,1に近いほどよい感じがしますね。実際に,平行テスト法や再テスト法的な意味での\(\rho\)は,1に近いほど良い指標です。一方で,内的一貫性としての信頼性係数は,1に近すぎるとかえって良くないとされています。というのも,「内的一貫性」という言葉から想像できるように,\(\alpha\)係数が1になるのは全ての項目が全く同じものを測定しているような場合です。言い換えると,全ての項目間の相関係数が1の場合になります。 相関係数が1ということは,一方の値によってもう一方の値が完全に説明可能な状態にあるため,実質的に1項目の回答だけわかれば尺度内の残りの全項目の回答が分かってしまう状態です。つまり1項目だけあれば十分であり,尺度として何項目も用意した意味がなくなってしまうことになります。 本来,構成概念の多くは普通に1項目で聞いただけでは十分に測定できないために,その構成概念を表す様々な側面に関する質問を重ねることによって,その共通成分としてあぶり出そうとしています。 それなのに1項目分しか機能していないとしたら,それは尺度の失敗と言っても良いでしょう。
一方,最低でもどの程度の信頼性が欲しいかですが,これも一貫した答えはまだありません。\(\alpha\)係数について言えば,項目数の影響を受けるため,一概にどれだけあれば良い,という話は出来ないはずです。世間では0.7だの0.8だの0.9だの言っている人がいるようですが,最終的には信頼性も連続的な指標のため,明確な閾値を考えるよりは,ありのままの値を報告するくらいの気持ちでいたほうが健全だと思います。…とはいいつつ「少なくとも0.7くらいは欲しいかなぁ」という個人的な気持ちもあったりしますが…
ということで,各項目の分析および尺度の信頼性(・妥当性)のチェックが無事完了したら,いよいよ分析の本編に進むことができます。 次のChapterでは,まずその先で紹介する因子分析・構造方程式モデリング・項目反応理論に通底する「回帰分析」の考え方についておさらいしながら,記法の導入などをしていきます。
本気できれいな図を作りたい場合は,
ggplot2というパッケージがおすすめです。ただ,この授業で紹介する方法とは設計の基本理念から異なっているので,紹介しているヒマがありません。論文用の図を作りたい時が来たら個別に質問してください。↩︎実は,
apply(dat, 2, mean)と同じ挙動をする,つまり列ごとの平均を出す関数としてcolMeans(dat)というものもあります。そしてrowMeans()やcolSums()という関数もあります。↩︎一般的に信頼性(および妥当性)は尺度全体の性質(または尺度全体\(\times\)母集団の組み合わせに対する性質)として考えられるものなので,項目ごとの性質の分析であるI-T相関の確認は信頼性とは別枠で紹介しています。↩︎
ncol(dat)+1列目を指定して代入することも可能ですが,この場合列の名前を決められないのでやめたほうが良いでしょう。↩︎もちろん,回答者自身が自分の潜在特性の強さと項目の閾値の関係を考えて回答を選んでいるわけではありません。あくまでも「こう考えたらしっくり来るよね」というイメージ的なものです。↩︎
それなりの項目数があれば,合計点は連続変数とみなしても良いのでそのまま使います。↩︎
polyserial()関数は,「カテゴリカル変数と連続変数の相関を出す」関数です。したがって,ポリシリアル相関の特殊なケース(カテゴリカル変数が二値)である点双列相関もこの関数で対応可能です。 これとは別に,polychoric()関数というものも用意されています。こちらは「カテゴリカル変数同士の相関を出す」関数で,ポリコリック相関とテトラコリック相関係数を出すことができます。↩︎現実のデータで,これだけきれいにI-T相関が高く出て(今後やりますが)きれいな因子構造が得られることはまずありません。この授業ではかなり理想に近いデータを扱っていたんだということは,みなさんもいずれ痛感するときが来るかもしれません。↩︎
formula記法は回帰分析やSEMのところでガンガン使用するので,少しでも慣れておくと良いでしょう。↩︎そして関数の挙動が思った通りにならない場合は,変数の型の間違いを疑うのも一つの手だということです。↩︎
以前も紹介しましたが,発表や論文用に図を作る場合は,
ggplot2というパッケージがおすすめです。plot()はあくまでもサッと図を作る用,と思っておくと良いと思います。とはいえもちろんplot()を駆使してきれいな図を作ることも可能です。お好きな方法を選んでください。↩︎かの有名な?プログラマーの三大美徳においても,一番目に「怠惰(laziness)」が置かれています。これは,本当に怠惰であれというわけではなく,全体としての作業量を減らせ,という意味です。コードを数十回もコピーするくらいなら,関数化して一回書くだけで済むようにしたほうが,結果的に全体の作業量は減るということです。↩︎
もちろん,慣れてきたら「
cut2()でいくつのグループに分けるか」や「プロットの色・太さ」なども変えられるようにもできます。↩︎一応,エラーメッセージには
variablelengthsdifferと表示されています。formula記法では,回帰分析のように左辺と右辺のデータの数は同じになっている必要があるのですが,"Q1_1" ~ groupとなった場合に,右辺はdat$groupつまりdatの行数の長さのデータがある一方で,左辺は(dat$Q1_1ではなく)"Q1_1"という長さ1の文字列になっているために,「変数の長さが違うよ」というエラーが出ているわけです。↩︎【おまけ1】の考え方からすると,もっと関数化してシンプルに書くことも可能です。もし暇なら,どのくらいコード量で作成できるか挑戦してみてください。↩︎
妥当性に関する議論については他にも, Borsboom et al. (2004) や Borsboom (2005 仲嶺監訳 2022) なども参考になると思います。↩︎
まあそんなものは理想論なのかもしれません。妥当性の定義についても未だに議論は尽きません。重要なのは,先行研究のやり方が常に正しいと思うな,もっと良い妥当性の証拠はあるかもしれないぞと常に考え続けることなのかもしれません…。↩︎
2026年現在,改訂作業が進んでいるとのことなので,数年後にはまた変わっているかもしれません。↩︎
因子分析やSEMの結果からCRやAVEと言われる指標を算出し,これが所定の値より高いことをもって「収束的妥当性が示された」という書き方をしているものがちょくちょく見られます。↩︎
もちろん,下位概念の構造を含めてそっくりそのままコピーしたような別の構成概念が存在している可能性は否定できません。つまりCRやAVEだけで満足しているものは正直言うと「不十分」だと思っています。↩︎
なおスピアマン・ブラウンの公式は,尺度の半分に対する信頼性\(r_{x_1,x_2}\)を補正することで,尺度全体での信頼性を求めようとしています。その点はちゃんと気をつけています。↩︎
私は長いことKR-20が「全ての折半で算出される\(\rho_{sh}\)の平均値」として提案されたものだと思っていたのですが, Kuder & Richardson (1937) の脚注をきちんと読むと,「平均値が計算できたらいいんだろうけど,その平均値を計算することが難しい」(ために別のアプローチとしてKR-20が提案された)ということが書かれていました。↩︎
一応,尺度全体において,項目レベルで(本質的)タウ等価(タウ,つまり真値が同じか,個人によらず一定のズレがある状態)であれば,\(\alpha\)係数は「平行テスト法」による真値\(\rho\)に一致するのですが,そうでない場合は,\(\rho\)を過小推定することが知られています。↩︎
たぶんその場合は,下位概念を導入して複数因子の構造を考えるのが良いかもしれませんね。↩︎