チャプター 2 では,データを読み込み,元データのレベルでのチェックを行いました。 ただ,まだデータを確認しただけで,このまま分析しても思ったような結果が得られない可能性があります。 というのもデータには多かれ少なかれノイズ(ゴミ)が混ざっており,そのまま残しておくと今後の分析に良くない影響を与えかねません。 ということで今回は主にデータの前処理を行っていきたいと思います。
データの読み込み
まずは前回保存したデータを読み込みましょう。 .rdsファイルを読み込む場合には,readRDS()関数を使います。
もしsave()やsave.image()関数で保存した.rdataファイルを読み込みたい場合には,load()関数を使います。
load()関数では,代入の記号(<-)を使用していません。これは,save()関数で保存した.rdataファイルにはオブジェクトが中身から名前まで丸ごと保存されており,load()関数はそれを丸ごと読み込んでいるためです。一方saveRDS()関数で保存した場合にはオブジェクトの中身だけが保存されるため,保存前と別の名前をあてても問題ないわけです。そういった理由から,保存する際の拡張子を.rdsと.rdataと使い分けています(と私は思っています)。
3.1 欠測値の処理
はじめに無回答の処理の仕方について少し説明します。一般的に分析の際には,無回答は欠測値 (missing value) として扱われます。テクニカルな話をすると欠測値には以下の3つのタイプがあり,そのタイプに応じた対処が求められます (Schafer & Graham, 2002) 。 ここでは,「体重」を尋ねた質問への無回答を例に考えてみましょう。
- MCAR
-
Missing Completely At Random とは,欠測値が完全にランダムに発生している状態です。簡単にいえばたまたま体重を記入し忘れた,という場合や明らかに異常値であるためにデータが使えない場合にはMCARとして扱うことが出来ます。
- MAR
-
Missing At Random とは,欠測値がその変数以外に関連して発生している状態です。体重で言えば,女性の方が体重を答えるのをためらう傾向が強いと思われるので,「女性の方が体重の欠測が多い」と考えられる場合はMARとして扱います。 名前に”At Random”と入っているのが少し違和感かもしれませんが,MARでは一応欠測の発生は確率的に発生する(ただし発生確率が他の変数によって変わる)と考えています。
- MNAR
-
Missing Not At Random とは,欠測値がその変数自体に関連して発生している状態です。体重で言えば,肥満傾向の人のほうが体重を答えるのをためらう傾向が強いと思われるので,「肥満の人の方が体重の欠測が多い」と考えられる場合や,体重計のスペック的に「測定不能」となってしまった場合はMNARとして扱います。
具体的な対処法まで話すと長くなってしまうので省略しますが1,簡単に言うとMNARでなければ統計的に欠測値を埋める方法があると考えて良さそうです2。したがって,特定の属性について欠測値が多くなっていてもバイアスを補正した推定が可能となるわけです。ということで,質問紙調査を行う段階で,MNARが発生しそうなセンシティブな項目などには特段の注意が必要となります。
実際にデータで見られた欠測がどのタイプなのかについては,ドメイン知識やデータの状況などによって総合的に判断する必要があります。 先程説明したように,同じ「体重」という変数をとっても,その背後に異なるメカニズムを想像するだけでどのタイプにも該当しそうでした。 というわけで,欠測値のタイプを判断するための統計的な指標は今のところほぼ存在しないと思います3。 ちなみに今回のデータにおける欠測値を考えてみると,
- 心理尺度の25項目に関する欠測値はMCARと考えてもよさそう
educationの欠測はMNARのような気もするけど…
という感じでしょうか。とりあえず心理尺度の25項目に関してはMCARとみなして,以後の分析では「25項目の中には欠測値がない人」だけを残して使用したいと思います。今回は全体で2800人いるので,多少減っても問題ないでしょう。
ただし,一つでも欠測値がある人を除外する場合は,事前に項目ごとの無回答率を確認しておいたほうが良いです。もしかしたら特定の項目が回答しにくくて無回答を誘発していたり,後半の設問ほど無回答率が高くなっていたり…ということがあるかもしれません。こうした状態を無視して機械的に除外してしまうと,「特定の項目に回答できる人」や「飽きっぽくない・回答が早い人」が多めに残ってしまい,何らかの偏りが発生してしまう可能性もあります。
Rでは欠測はNAとして扱われています。そのため,列ごとにNAとなっているデータの数(割合)を計算することで無回答率が算出できそうです。 ちょっと厄介なのは,NAは比較演算では特殊な挙動をする,という点です。 「NAと一致するか」はシンプルに考えると等号(==)を用いて以下のように書けそうですが,実際にはそうはいきません。
このように,NAとの比較は「判断不能」的な感じで結果もNAになってしまいます。 代わりにRには,NAかどうかを判断する関数として,is.na()という関数が用意されているのでこれを使いましょう4。 is.na()関数は,引数に与えたものに関して,NAであればTRUE,そうでなければFALSEを返します。ベクトルや行列・データフレームを与えた場合はその要素ごとにTRUE/FALSEを出してくれます。
これを使えば,それぞれの値が「NAであるか」を判定できるようになります。 あとはNAの数を数えるだけです。
is.na()関数の出力はlogical型(TRUE/FALSEしかとらない)のベクトルなのですが,実は内部的にはTRUEは1,FALSEは0としても扱われます。
[1] TRUE TRUE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE FALSE
[12] TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[23] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE
[34] TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[45] FALSE FALSE FALSE FALSE FALSE FALSE
[ reached 'max' / getOption("max.print") -- omitted 2750 entries ]そのため,is.na()の出力は何も考えずにそのままmean()に突っ込むことで,TRUEの割合(無回答率)がカウントできます。 同様に,sum()をとればTRUEの人数(この場合欠測の人数)をカウントすることも可能です。
ということで,あとはこれを全項目に対して適用していけば良いのですが,下のように全部書いていてはキリがありません。今回はIDを除いて28項目なのでまだなんとかなりますが,数百項目になったらどうしましょう。
このような場合に備えて「一気に複数の列(または行)に同じ処理を施す方法」を紹介します。 apply()関数は,データフレーム・行列・多次元配列について,指定した次元(行または列)にそれぞれ同じ関数を適用するという関数です。 …よくわからないと思うので実際にやってみましょう。まずは以下のコードと出力を見てみてください。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10 Q1_11 Q1_12
[1,] 1 2 4 3 4 4 2 3 3 4 4 3 3
[2,] 2 2 4 5 2 5 5 4 4 3 4 1 1
[3,] 3 5 4 5 4 4 4 5 4 2 5 2 4
Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19 Q1_20 Q1_21 Q1_22 Q1_23
[1,] 3 4 4 3 4 2 2 3 3 6 3
[2,] 6 4 3 3 3 3 5 5 4 2 4
[3,] 4 4 5 4 5 4 2 3 4 2 5
Q1_24 Q1_25 gender education age
[1,] 4 3 1 NA 16
[2,] 3 3 2 NA 18
[3,] 5 2 2 NA 17
[ reached 'max' / getOption("max.print") -- omitted 3 rows ]head(dat)のときと同じような結果になりました。この時,裏では 図 3.1 のような処理が行われています。つまりhead(dat[,1]),head(dat[,2]),…をという感じで列ごとに同じ関数を適用し,その結果をまとめているのです。
apply(dat, 2, head)の挙動
apply()は基本的に3つの引数からなります。apply(X, MARGIN, FUN)
X-
関数を適用する元データです。
MARGIN-
どの次元に関して,それぞれ関数を適用するかを指します。数字はデータフレームにおける要素の指定
[ , ]のときの順番と同じです。したがってMARGIN = 1の場合は行ごと,MARGIN = 2の場合は列ごとに関数を適用します。 FUN-
どの関数を適用するかです。もしその関数が別の引数を取る場合は,この後に引数を続けて書いていきます。
では,当初の目的である「datの列ごとにNAの割合を出したい」場合にはどうしたら良いでしょうか。 引数を一つずつあてはめていくと,Xにはis.na(dat)を,MARGINには2(列ごと)を,FUNにはmeanが入れば良さそうです。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
Q1_10 Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[ reached 'max' / getOption("max.print") -- omitted 2797 rows ] ID Q1_1 Q1_2 Q1_3 Q1_4
0.000000000 0.005714286 0.009642857 0.009285714 0.006785714
Q1_5 Q1_6 Q1_7 Q1_8 Q1_9
0.005714286 0.007500000 0.008571429 0.007142857 0.009285714
Q1_10 Q1_11 Q1_12 Q1_13 Q1_14
0.005714286 0.008214286 0.005714286 0.008928571 0.003214286
Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
0.007500000 0.007857143 0.007500000 0.003928571 0.012857143
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24
0.010357143 0.007857143 0.000000000 0.010000000 0.005000000
Q1_25 gender education age
0.007142857 0.000000000 0.079642857 0.000000000 educationの無回答率が0.079642857,つまりおよそ7.96%とやや高いですが,25項目中には無回答率の高い項目はなかったので,予定通り進めていきます。
欠測値があるレコードを取り除く関数としてはna.omit()というものがあります。 ですがこの関数は一つでも欠測値がある行は全て除外するため,na.omit(dat)としてしまうとeducationがNAの人(つまり最終学歴を答えることに抵抗がある層)もごっそりと抜け落ちてしまいます。 今は25項目の中に欠測がある人だけ取り除きたいので,ここではsubset()に適切な条件式を与えることで目的を達成していきましょう。材料は以下の関数たち+is.na()+apply()です。
これらを組み合わせると,以下のようにして目的を達成できます。最後の結果をdatに代入するのを忘れないように気をつけてください。
Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
[1,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[2,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[3,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[4,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19 Q1_20
[1,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[2,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[3,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[4,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
Q1_21 Q1_22 Q1_23 Q1_24 Q1_25
[1,] TRUE TRUE TRUE TRUE TRUE
[2,] TRUE TRUE TRUE TRUE TRUE
[3,] TRUE TRUE TRUE TRUE TRUE
[4,] TRUE TRUE TRUE TRUE TRUE
[ reached 'max' / getOption("max.print") -- omitted 2796 rows ] [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE TRUE TRUE
[12] FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[23] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[34] TRUE FALSE TRUE TRUE TRUE TRUE TRUE TRUE FALSE TRUE TRUE
[45] TRUE TRUE TRUE TRUE TRUE TRUE
[ reached 'max' / getOption("max.print") -- omitted 2750 entries ]もちろん,上記の処理を全て1行にまとめてdat <- subset(dat,apply(!is.na(dat[,paste0("Q1_",1:25)]),1,all))なんて書いてもOKです。でも読みにくいですねェ5。
きちんとNAがなくなっていることを確認するために,再度各列のNAの割合(または個数)をカウントしてみましょう。 Q1_1からQ1_25が全て0になっていればOKです。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5
0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000
Q1_6 Q1_7 Q1_8 Q1_9 Q1_10 Q1_11
0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000
Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17
0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000
Q1_18 Q1_19 Q1_20 Q1_21 Q1_22 Q1_23
0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000
Q1_24 Q1_25 gender education age
0.00000000 0.00000000 0.00000000 0.08210181 0.00000000 最後に,欠測値を除外した後のデータフレームのサイズを確認しておきましょう。上で紹介したstr()でも行数は出してくれるのですが,ここではまた別の方法で確認してみます。
nrow()関数は,例えば「データフレームの各行に順番に何か処理をしたい」という場合に,1:nrow(dat)という形で「行数だけの長さの整数ベクトル」を作ったりする場合に有用です。 この方法ならば,データのサイズが変わったとしてもコードを修正する必要が無い点がおすすめポイントです。 また,ncol()は,一番右の列を取り出したい時なんかにも使えます。というように,nrow()およびncol()はところどころ使うことがあると思うので覚えておきましょう。
3.2 適当な回答を除外する
調査においては,全ての回答者が必ず誠実に回答してくれるとは限りません。 特にウェブ調査では,驚くほど不真面目な回答が見られるものです。 人間は基本的にラクをしたい生き物なので,一部の人は調査に回答する際に「なるべく認知的なリソースを使わずに回答してしまおう」と考えることがあり,これを努力の最小限化 (satisficing: Krosnick, 1991) と呼びます。
調査を行う人達は,長い間この「努力の最小限化」に対抗するために様々な方法を考えてきました (e.g., Curran, 2016)。 ここでは,明らかな適当回答を除外するためのいくつかの方法を紹介し,最後に実際に除外を行ってみます。
3.2.1 指示項目
質問紙を作る段階の話ですが,「この項目は一番右を選んでください」など,尺度の内容とは無関係に回答を指示する項目や,「私はここ1ヶ月寝ていない」など回答が絶対に一つに決まるはずの項目を入れておく,というのが最も簡便に利用可能な検出方法だと思います。ただ,1問だけの場合,たまたま適当に指示項目を通過してしまう可能性があるため,鬱陶しくならない程度に複数個入れておくと良いかもしれません。 また,Web調査で項目をランダマイズする場合には,指示項目が一番上に来ないように,指示項目だけ表示順を固定するなど気をつけると良さそうです。
指示項目を使用した場合には,その項目についてsubset()を使えば良いので除外も簡単ですね。除外する際には,論文に記載するために何%もしくは何人がそこで脱落したかを数えておきましょう。 Rでカウントする際には,以下のような方法が考えられます。
また,IMC (Instructional manipulation check, Oppenheimer et al., 2009) と呼ばれる方法も同じような効果を持ちます。この方法では,項目ではなく教示文に特別な指示を入れます。 図 3.2 では,項目自体は「よくやる運動」を尋ねているのですが,IMCでは「タイトル(Sport Participation)をクリックしてね」という指示を与えています。 その結果,元論文では46%もの人が引っかかってしまい,スポーツ名や下の”Continue”をクリックしてしまったそうです。 IMCは心理尺度の中に混ぜると言うよりは,例えば教示として状況や特定の物事に関する説明文をおく必要がある場合に使えそうな方法と言えます。長い説明文の最後か途中に「この内容を読んで正しく理解できた方は,この後の『正しく理解できた』の項目で『いいえ』を選択してください」や「次の段落の最初の文字をマルで囲んでください」のような指示を入れておく,といったやり方が考えられます。
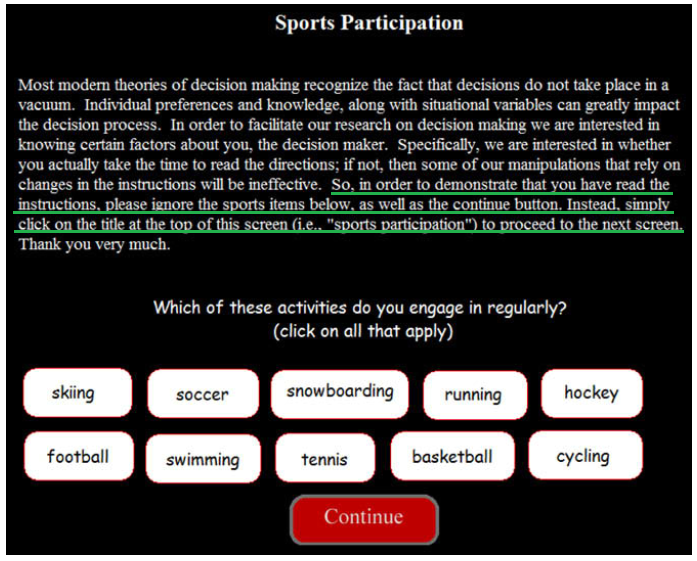
ただ,IMCは場合によっては半数以上,多い時で8割以上も引っかかってしまうことがある (三浦・小林,2016) ので,最終的なサンプルサイズが小さくなりすぎないように気をつける必要があるかもしれません。 裏を返せば,それだけウェブ調査はまともに回答されていない,ということなのかもしれませんが…。
3.2.2 回答時間
Web調査の場合,回答時間のデータも取得可能です6。回答時間を用いて適当回答を除外する場合,基本的には閾値を設けて,早すぎる・遅すぎる回答者を除外するという方法がとられます (e.g., Huang et al., 2012)。 一般的に回答時間を用いる場合,一項目ごとの時間を収集することが望ましい (OIOS: One-item-one-screen)とされています。 これは,例えば後半で疲れてしまいその後の回答が適当になってしまった場合を検出できるなど,回答行動内での動きをきめ細かくチェックできるようになるためです。
実際にどの程度の閾値を用いるかはケースバイケースです。 単純に設問文が長い項目だったり,内容的に複雑な思考を必要とするような項目では所要時間は必然的に長くなるでしょう。 一部の研究では,内容的に絶対にまともに回答することができないであろう時間(3秒など)を閾値とする考え方 (Kong et al., 2007) なども提案されていますが,多くの先行研究ではデータから閾値を動的に決めています。 Höhne & Schlosser (2018) では,先行研究で用いられた閾値のいくつかを 表 3.1 のようにまとめてくれています。
| 下側の閾値 | 上限の閾値 |
|---|---|
| 平均値\(-2\times\mathrm{SD}\) | 平均値\(+2\times\mathrm{SD}\) |
| 中央値\(-1.5\times\)四分位範囲 | 中央値\(+1.5\times\)四分位範囲 |
| 中央値\(-1.5\times\)(中央値\(-\)第1四分位点) | 中央値\(+1.5\times\)(第3四分位点\(-\)中央値 |
| 中央値\(-3\times\)(中央値\(-\)第1四分位点) | 中央値\(+3\times\)(第3四分位点\(-\)中央値) |
| 下側1% | 上側1% |
ということで,回答時間をもとに適当回答を検出するためには,分位点を計算できるようになっておくと良さそうです。 Rではお好きな分位点を以下のように求めることが出来ます。
quantile(): 分位点を求める
実際にデータを除外する場合には,1項目でも基準に引っかかったらアウト,とはしないことが多いです。 複数の項目の回答時間(引っかかった項目数)に加えて,この後紹介するような方法によって実際の回答内容を見ながら総合的に判断していきます。
そして閾値の決め方に正解はありません。「疑わしきは罰せず」の姿勢でいった場合には適当回答の影響で回答の分布が歪むかもしれない一方で,「疑わしきは罰する」の姿勢の場合には一部の真面目な回答も除外してしまうために回答の分布が歪む可能性があります。余裕があれば,いろいろな閾値のもとで同じ分析を行って結果が変わらないことを確認(感度分析)すると良いでしょう。
3.2.3 回答内容の不一致
項目の組み合わせや回答方法次第では,回答内容の不一致によって疑わしい人を検出できるかもしれません。例えば今回使用しているデータにはageとeducationという項目があります。海外ならば飛び級制度があるので一概にルールを決めるのは難しいですが,日本であれば1年だけ「飛び入学」または「早期卒業」が可能なようです。ということは,「17歳未満の高卒以上」や「20歳未満の大卒」は日本のルール的には不可能なため,そのような回答をしている人は怪しいかもしれません。 ただし,これは少なくとも年齢または学歴の項目について適当に回答または記入ミスがあるというだけであり,心理尺度の部分は正しく回答している可能性も十分にあります。 そのため,上記のような「1つのミス」によって該当者の全ての回答を除外するかは要検討です。例えば,「学歴によって因子構造が変わるか」を検証したい場合であれば,学歴が正しく記入されていない可能性のあるデータは使用できないでしょう。というように,目的に応じて使うかどうかを決めるのが良さそうです。
他にも,成人のADHDを診断するための尺度であるCAARS (Conners’ Adult ADHD Rating Scales: Conners et al., 1999) には矛盾指標というものが用意されています。 これは,例えば「1つの場所に長時間いることが難しい」と「じっと座っているときでも,内心は落ち着かない」のように,普通に考えたらだいたい同じ回答が得られそうな項目ペアについて差得点を出すことで,誠実に回答しているかを判断する方法です。 特定の構成概念を測定するための一般的な心理尺度では,CAARSの矛盾指標のように確立された項目対が用意されているわけではないですが,通常全ての項目が同じような内容を尋ねているわけですから,同じような考え方で,あまりにも回答が不安定な人は怪しい,と判断できるかもしれません。
ということでここからは,不適切回答を検出するためのいくつかの手法を提供しているcarelessパッケージを用いたやり方を紹介していきます。
同じ構成概念を測定しようとしている心理尺度の場合,内容をきちんと読んで回答しているならば,基本的には各項目に対して同じような選択肢(例えば全て「あてはまる」寄り)を選ぶはずです。 言い換えると,そのような場合には回答の個人内標準偏差が小さくなっていると考えられます。 …という考え方に基づいているのがIntra-individual Response Variability (IRV: Dunn et al., 2018)です。 大層な名前がついていますが,やっていることは単純な標準偏差です。 carelessパッケージにはirv()という関数が用意されています。
irv(): 尺度内標準偏差を求める
1 2 3 4 5 6 7
0.8944272 1.5165751 0.5477226 0.8366600 1.1401754 0.5477226 1.4142136
8 10 11 13 14 15 16
1.7888544 1.6431677 0.8366600 0.7071068 0.5477226 1.6431677 1.5165751
17 18 19 20 21 22 23
1.6733201 0.4472136 0.7071068 0.8366600 1.6431677 2.5884358 2.0736441
24 25 26 27 28 29 30
1.6431677 0.7071068 2.7386128 0.8944272 1.7320508 1.7888544 0.7071068
31 32
2.1679483 1.7320508
[ reached 'max' / getOption("max.print") -- omitted 2406 entries ]irv()の基本的な挙動は,与えられたデータに対して行ごとに標準偏差を取っているだけなので,先程のコードを今までに登場した関数で表せばapply(dat[,paste0("Q1_",1:5)], 1, sd)と同じことです。 一応irv()関数は他にも,引数次第で「前半のIRV」「後半のIRV」というようにデータを等分割してそれぞれのパートでのIRVを出してくれる機能もあります。 調査で言えば,途中で疲れて後半が適当になっている人を検出したり,datの25項目のように複数の異なる特性に関する項目が並んでいる場合には役に立つかもしれません。
irvTotal irv1 irv2 irv3 irv4 irv5
1 0.900000 0.8944272 0.8366600 0.5477226 0.8366600 1.3038405
2 1.294862 1.5165751 0.7071068 2.1213203 1.0954451 0.8366600
3 1.092398 0.5477226 1.2247449 1.0954451 1.1401754 1.5165751
4 1.166190 0.8366600 0.8366600 0.7071068 1.6431677 0.8944272
5 1.000000 1.1401754 1.1401754 1.5165751 0.8366600 0.4472136
6 1.863688 0.5477226 2.3021729 2.3452079 1.2247449 1.9235384
7 1.607275 1.4142136 1.1401754 0.8366600 0.5477226 2.1679483
8 1.519868 1.7888544 1.0000000 1.9235384 1.7888544 1.1401754
[ reached 'max' / getOption("max.print") -- omitted 2428 rows ]3.2.4 ストレートライン
上で説明したように,心理尺度では,内容をきちんと読んで回答しているならば,基本的には同じ選択肢を選ぶはずです。 とはいえ,完全に同じ選択肢を選び続けると言うよりは,細かい内容の違い等によって,少しずつ異なる回答をすることが期待されています7。 リッカート尺度は表形式で尋ねることが多く,そのようなフォーマットに対する努力の最小限化は,縦一列に同じ選択肢を選び続けるという形で表れると考えられます。 特に逆転項目(「~ではない。」のような項目)があるにも関わらずそれを無視して同じ選択肢を選び続けている場合は要注意です。
このように「ずっと同じ選択肢を選び続けている」状態をストレートラインやlong stringなどと呼びます。 一般的には,ずっと同じ選択肢を選び続けた最大の長さ (long string index) を計算して,これが閾値より大きい人は要注意,という感じで利用します。 long string indexをRで計算するのは結構骨が折れる作業なのですが,carelessパッケージにはlongstring()という関数が用意されています。ありがたい。
longstring(): 最長の同一回答数を計算する
実際にIRVやlong string indexを除外基準として利用する場合の閾値は,やはりケースバイケースです。 一つの方法としては,ヒストグラムを作成して視覚的に決めるのが良いでしょう。
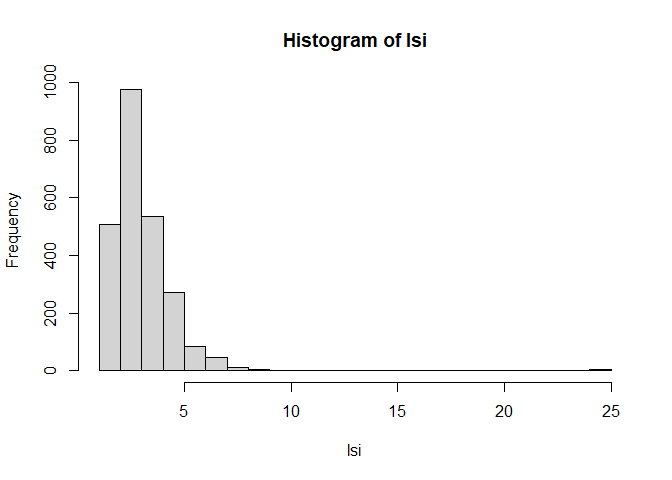
図 3.3 を見ると,大体7か8くらいより大きい人は怪しそうな気がします。 ヒストグラムの他にも,quantile()関数を使って上位何%の人が怪しい,といった検出方法も考えられますが,いずれにしてもlong string index(やirv)の値だけで機械的に除外するのではなく,可能な限り回答の内容も踏まえて除外するかを決めるようにしましょう。
ちなみに,今回のデータでは項目の出題順は個人ごとにランダムであったと思われます。 このような場合,ストレートラインによる除外は意味を成さないので気をつけてください8。 また,ストレートラインと似た適当回答としては,複数個でパターンを繰り返すもの(e.g., 123451234512345…)や,階段状に回答するもの(e.g., 2345432345432…)などもあります。本当はこれらも全部検出してあげるのがベストなのですが,残念ながらlongstring()関数では対応できないので,自分で関数を作成する必要があります。 これはめちゃめちゃ面倒なので今回は省略します9。
longstring()関数を使わずにストレートラインを計算する
以下では,longstring()関数を使わずに最長ストレートラインを計算するコードの実装例を紹介します。 一応各ステップでの状態も載せておくので,各行で何が行われているか確かめながら読み進めてください。 また,やり方は他にも色々あるので,もしよければ自分で考えて実装してみてください。
これでようやく1人分の最長ストレートラインが計算できました。 本当はこれを(apply()などを使って)全員に対して計算した上で,一定数より大きい人を除外するか検討する,といった手続きを取る必要があるわけです。
3.2.5 人と違う回答
心理尺度の場合,同じ構成概念を尋ねている各項目はそれなりに相関しているはずです。もちろん項目によってそもそも当てはまりにくい・当てはまりやすい項目はあるのですが,総合すると項目への回答には「平均的なパターン」と言えるものがありそうです。「人と違う」を検出する方法は,異常検知の知見が使えたりします。したがって機械学習を利用して検出する方法なども研究されていたりしますが,ここでは伝統的なマハラノビス距離を用いた検出方法を紹介&実践してみたいと思います。
図 3.4 は,2項目の連続的な項目(6段階評価ではなく,スライダーみたいなもので回答したと想像してください)への回答をプロットした仮想的なものです。赤い点がそれぞれの軸の平均値を表しています。青い点(1)と(2)は,それぞれ赤い点からの直線距離はほぼ同じなのですが,2変数の相関を考えると(2)の方はさほどおかしな値ではなさそうです。正の相関があるため,平均値から離れていたとしても2項目とも一貫して高い or 低い値ならばありえる,ということですね。
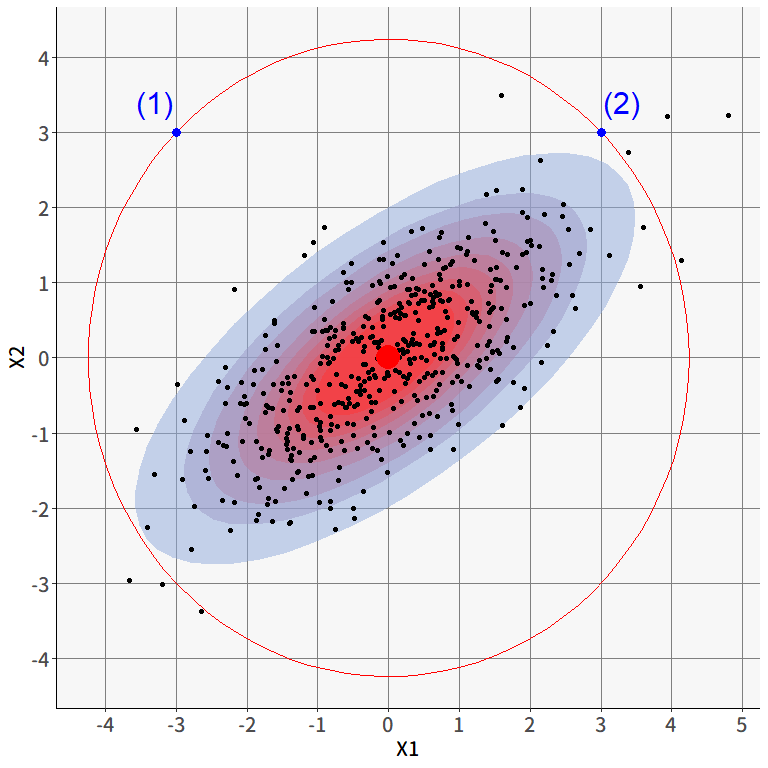
このような時に使えるのがマハラノビス距離です。変数の相関関係を考慮した上でベクトル間の距離を出してくれます。回答者\(i\)の回答ベクトルを\(\symbf{x}_i\),全回答者の平均ベクトルを\(\bar{\symbf{x}}\),変数の分散共分散行列を\(\symbf{\Sigma}_{\symbf{x}}\)とすると,マハラノビス距離は \[ \begin{aligned} D=\sqrt{(\symbf{x}_i-\bar{\symbf{x}})\symbf{\Sigma}_{\symbf{x}}^{-1}(\symbf{x}_i-\bar{\symbf{x}})^{\top}} \end{aligned} \tag{3.1}\] で計算することが出来ます。 マハラノビス距離は,多変量正規分布と密接な関係を持っています。 というのも,\(k\)個の変数に関する多変量正規分布の確率密度関数は \[ \begin{aligned} f(\symbf{x};\symbf{\mu},\symbf{\Sigma})=\frac{1}{\sqrt{(2\pi)^k |\symbf{\Sigma}|}}\exp\left(-\frac{1}{2}(\symbf{x}_i-\symbf{\mu})\symbf{\Sigma}_{\symbf{x}}^{-1}(\symbf{x}_i-\symbf{\mu})^{\top}\right) \end{aligned} \tag{3.2}\] と表されますが,よく見るとこの式の中には(3.1)式のルートの中身によく似たものが入っています。 実際に,データから多変量正規分布の平均ベクトル\(\symbf{\mu}\)と分散共分散行列\(\symbf{\Sigma}\)を最尤推定する場合,最尤推定量はそれぞれ標本平均ベクトル\(\bar{\symbf{x}}\)と標本共分散行列\(\symbf{\Sigma}_{\symbf{x}}\)となることが知られています。 したがって,マハラノビス距離はデータから推定された多変量正規分布の確率密度に反比例するということがわかります。 言ってしまえば,マハラノビス距離は個人レベルでみたときの尤度みたいなもの,というわけですね。 図 3.4 で言えば,塗りつぶされている楕円が,データから推定されたニ変量正規分布における大まかな確率密度を表していますが,マハラノビス距離はこの確率密度に応じて計算されているわけです。 そう考えると,確かに(2)の点のほうが(1)の点よりも中心からの距離は短い,と判断できそうです。
Rにはマハラノビス距離(の二乗)を計算するための関数mahalanobis()が用意されているため,これを使って 図 3.4 の2つの青い点のマハラノビス距離を計算してみます。mahalanobis()では,基本的に3つの引数をとります。第一引数xには\(\mathbf{x}_i\)を,第二引数center10には\(\bar{\mathbf{x}}\)を,第三引数covには\(\symbf{\Sigma}_{\symbf{x}}\)に相当するものを入れてあげましょう。
ということで,青い点(1),(2)と平均ベクトルとのマハラノビス距離(の二乗)はそれぞれ180,9.47となり,たしかに(1)のほうが大きな外れ値であるということがわかりました。
ありがたいことにcareless()パッケージには,データフレームからマハラノビス距離を計算するための関数も用意されています。 先程使用したmahalanobis()関数では,自分でデータから平均ベクトルと分散共分散行列を計算する必要があったのですが,carelessパッケージにあるmahad()関数ではデータフレームを一つ与えるだけで各行のマハラノビス距離をまとめて計算してくれます11。ありがたい。
[1] 13.468425 25.677291 13.490783 28.823203 18.946470 25.901522
[7] 9.260945 48.474541 12.794634 19.207672 19.386422 14.485101
[13] 34.052697 38.710674 18.843160 18.056494 26.822273 38.451815
[19] 47.752717 30.685610 24.097729 27.202401 10.453943 30.186948
[25] 20.393634 12.667231 45.024926 23.116322 26.807564 12.173940
[31] 56.951093 20.122730 26.353218 30.358047 17.898820 28.093556
[37] 14.465344 10.483335 11.724812 27.950268 7.693067 57.603758
[43] 23.731495 20.956441 42.950337 14.636132 32.755405 52.321123
[ reached 'max' / getOption("max.print") -- omitted 2388 entries ]これで無事,全員分のマハラノビス距離を一気に計算できました。あとはこれを利用して怪しい人を検出するだけです。 ですがこの場合でも閾値の問題が登場します。 これまで通り,ヒストグラムを描いてみたり,quantile()を利用してみても良いのですが,mahad()関数にはもう少しテクニカルな方法が実装されています。
\(p\)次元多変量正規分布に従うデータから計算されるマハラノビス距離の二乗は,理論的には自由度\(p\)の\(\chi^2\)分布に従うことが知られています。 これを利用すると,「自由度\(p\)の\(\chi^2\)分布における上位\(k\)パーセンタイル点より大きい人を検出しよう」という考えに至ります。
d_sq flagged
1 13.468425 FALSE
2 25.677291 FALSE
3 13.490783 FALSE
4 28.823203 FALSE
5 18.946470 FALSE
6 25.901522 FALSE
7 9.260945 FALSE
8 48.474541 TRUE
9 12.794634 FALSE
10 19.207672 FALSE
11 19.386422 FALSE
12 14.485101 FALSE
13 34.052697 FALSE
14 38.710674 FALSE
15 18.843160 FALSE
16 18.056494 FALSE
17 26.822273 FALSE
18 38.451815 FALSE
19 47.752717 TRUE
20 30.685610 FALSE
[ reached 'max' / getOption("max.print") -- omitted 2416 rows ]ここでflagged列がTRUEになっている人が,マハラノビス距離が閾値より大きい,すなわち異質な回答パターンを示した人だということです。
ちなみに,マハラノビス距離が最大の人の回答ベクトルを見てみると,たしかにこの人は6か1かばかりで回答しており,どうやら適当に回答しているような気がします。 ただ実際には日頃から極端な選択肢を選ぶ傾向がある人かもしれないので,これだけで機械的に除外するのではなく,回答ベクトルを見てストレートラインの傾向が無いかなども確認して除外の判断をしたほうが良いでしょう。
マハラノビス距離は平均ベクトルからの距離を求めています。そのため,同じストレートラインでも1と6ばかりなど極端な選択肢を選んでいる人は引っかかりやすい一方で,3と4(どちらでもない周辺)ばかりを選んでいる人はどうしてもマハラノビス距離は小さくなってしまいます。同様に,どちらでもない周辺で適当な回答をしている人は検出しにくいという問題点があります。
これを克服するためには,マハラノビス距離に加えてIRVやストレートラインなどの指標,あるいは可能であれば回答データ以外(回答時間など)の複数の指標を組み合わせて検出してあげるのが良さそうです。
また,そもそもマハラノビス距離は,多変量正規分布の確率密度に比例する値であるという点にも注意が必要です。 天井・床効果程度なら多分問題ないのですが,例えば6件法で1と6(極端な選択肢)に回答が集中するような場合には,回答の分布が二峰になっているので,そもそも正規分布を当てはめることが怪しくなってきます。そのような場合にはマハラノビス距離を使うこと自体もよく考えたほうが良さそうです。
適当な回答(satisficing)を検出するためのより高度な方法は,もちろんすでに色々と提案されています。 例えば セクション 8.9.2 で紹介するような,モデルベースの個人適合度(尤度)を用いて統計的に適当回答を検出する方法はすでに多数提案されています。 また Biemann et al. (2025) では,ストレートラインだけでなく階段状のパターンや左右の端を行き来するようなパターンも含めて「内容よりも機械的なルールに従って選択されているか」を検出するために,マルコフ連鎖の遷移確率行列を用いた指標を提案しています。 他にも Pokropek (2026) では,実際の適当回答の際に見られる回答パターンをモンテカルロ法で生成したシミュレーションデータを用いて,サポートベクターマシン(SVM)や深層ニューラルネットワーク(DNN)による教師あり学習モデルを実行しています。
そして,近年のいわゆるAIの発展は凄まじいもので,すでにウェブ調査などではAIに「人間のふりをして回答させる」こともかなりできるようになっています。 ということで,今後数年間は,「AIによる回答であるか」を検出するための方法の開発が盛んに行われるようになり,またAI側もこれを回避するように進化していく,といういたちごっこが続いていくのではないかと予想されます。 そして,もしもAIによる回答を検出できなくなってしまった暁には,ウェブ調査は現在のような形式では成り立たなくなってしまう可能性もあるのではないかと個人的には思っています。こわいですね。
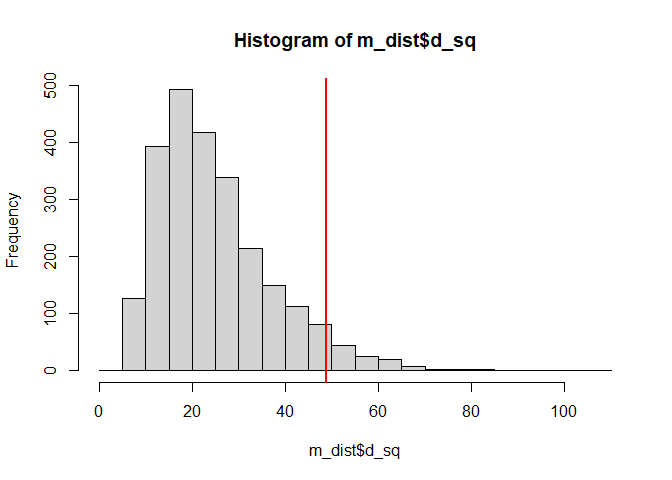
ここまで適当回答を検出するためのいくつかの方法を紹介してきました。 実際のデータにおいて検出&除外を行うときにはいろいろと考えるべきことはあるのですが,とりあえず今回は機械的に「long string index (lsi)が8以上」かつ「マハラノビス距離が上位5%12」の人を除外することにします。ちなみにマハラノビス距離の上位5%は,図 3.5 の分布でいえば赤い線より右側の人であり,極端に大きい人たちだろうということが言えそうです。
では,実際に2つの基準をともに満たす人を除外してみましょう。 ここでは,複数の条件式を結合するための論理演算子を使用します。 論理演算とは,複数のTRUE/FALSEをもとに1つのTRUE/FALSEを返す演算のことです。 何はともあれ,以下の例を見てください。
今回は,AND演算子 (&)を用いて「long string index (lsi)が8以上」かつ「マハラノビス距離が上位5%」の人を探し出したいと思います。
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[12] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[23] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[34] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[45] FALSE FALSE FALSE FALSE FALSE FALSE
[ reached 'max' / getOption("max.print") -- omitted 2386 entries ] ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10 Q1_11
1430 1430 1 1 1 1 1 1 1 1 1 1 1
1560 1560 1 6 6 1 1 5 6 6 4 6 1
2043 2043 1 1 1 1 1 1 1 1 1 1 1
2313 2313 6 1 1 6 1 6 5 6 1 1 6
Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19 Q1_20 Q1_21
1430 1 1 1 1 1 1 1 1 1 1
1560 6 6 1 6 6 6 6 6 6 6
2043 1 1 1 1 1 1 1 1 1 1
2313 6 1 1 1 1 1 1 1 1 6
Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1430 1 1 1 1 1 3 23
1560 6 4 6 1 2 5 31
2043 1 1 1 1 1 3 19
2313 1 1 6 1 1 3 23ということで,残ったデータは
となりました。以後の分析はこの2432人分のデータで進めていきます。
3.3 逆転項目の処理
心理尺度では,内容を読まずに「慣れ」でストレートライン的回答を避けたい,といった目的から意図的に「**ではない」のように否定語を使ったり,構成概念をきちんと反映した項目として,意味的に反対のことを尋ねる(例えば,社交性を測定する尺度において「休日は基本的に家から出ない」のような項目を入れておく)ことがあります。 こうした項目は逆転項目と呼ばれ,分析の際には,多くのケースにおいて事前に得点をひっくり返す必要があります。 psych::bfiでは131, 9, 10, 11, 12, 22, 25番目の項目が逆転項目となっています。
逆転項目の処理自体は何も難しいことはなく,リッカート尺度の場合は「(最大値+最小値)から回答の値を引く」だけでOKです。ということで,一つの列について逆転項目の処理を行うならば以下のコードで可能となります。
今回は7項目だけなので一つ一つやっても良いのですが,もっと項目数が多いと大変なのでapply()の力を借りましょう。 今回の場合,apply()関数の引数Xには「datのうち逆転項目を処理したい列だけ」,MARGINは2,FUNには「7から引く」という関数を指定してあげたら良いわけです。ですが困ったことにRには「7から引く」なんていうspecificな関数は存在していません。こういう時には,関数を定義するという方法を使う必要があります。 簡単な関数を定義している例を挙げてみましょう。
この関数tashizan()はもちろんRにもともと存在しない,与えられた2つの引数xとyの和を返す関数です14。同じ要領で,「7から与えられた値を引く」という関数を作りましょう。
これをapply()関数の引数FUNに指定してあげれば,すべての列に同じ処理を適用することができるわけです。
これで,ようやく全ての逆転項目の処理が完了しました15。 次章では,データの性質を確認して,収集したデータが「本当に使えるものなのか」を見ていきます。
欠測データの処理についての日本語の書籍としては,例えば 高橋・渡辺 (2017) にはRのコードも掲載されているので,興味があれば見てみると良いかもしれません。↩︎
MCARの場合には,最悪欠測値がある人をリストワイズ削除しても問題ありません(サンプルサイズが小さくなるだけでバイアスにはならない)。MARの場合には,多重代入法(MI)や完全情報最尤推定法(FIML)を用いると,うまいこと欠測値を補完することができるとされています。↩︎
一応MCARかどうかを判別するための統計的検定法としてLittle’s MCAR test (Little, 1988) というものがあるようです。Rには
BaylorEdPsych::LittleMCAR()という関数が作られているようです。使ったことはありません。↩︎Rでは,「あるはずなのに無い(欠測)」は
NA(Not Available),「数字ではないもの(e.g., 0で割ったもの)」はNaN(Not A Number),「もともと何もない」はNULL,無限大はInfという特殊な非数値が用意されており,それぞれis.***()関数で判定可能です。↩︎カッコがたくさんあると読みにくくなってしまいます。だからといって,途中のオブジェクトをいちいち変数に代入する場合,変数の名前を(ムダに)考える必要が出てきてしまいます。こういった問題をクリアするのが
パイプです。Rネイティブでも最近ようやく実装されました。例えばhead(dat)はdat |> head()という書き方が出来ます。パイプを使えば,処理の順番がわかりやすくなるかもしれません。↩︎最も手軽にWeb調査フォームを作成する場合はGoogle Formが選択肢に上がるかと思いますが,どうやらGoogle Formには回答時間を記録する方法はなさそうです…同じWeb調査作成プラットフォームの中では,Questantやqualtricsでは,項目ごとではなく回答全体での所要時間の記録が可能なようです(項目単位で記録できるかは不明)。あるいはjavascriptが使えるならば jsPsych といったフレームワークもあります。こちらは心理学系の実験が色々出来ますが,その一環として普通のアンケートも実装可能であり,javascriptによって記録できる行動は(画面遷移やマウスカーソルの座標なども)理論上全て取得可能です。↩︎
本当に全ての項目に同じ回答を期待しているのであれば,複数項目用意する必要が無いですからね。複数項目用意しているのは,1項目では構成概念を十分に測定しきれないためです。↩︎
ランダムに出題されていた場合には,左から実際の出題順に回答を並べたデータを用意できれば同様にストレートラインの計算が可能です。↩︎
気になる人は個人的に教えます。ただ相当大変なので覚悟してください。↩︎
ふつうマハラノビス距離は「2つのベクトルの距離」なので2つの引数は
xとyのほうがしっくり来るのですが,この関数の第二引数がcenterなのは,この関数が「データフレームの各行について,平均ベクトルからのマハラノビス距離を計算する」という,まさにいま行っている分析の目的にピッタリの関数だからです。↩︎内部の計算は
psych::outlier()関数を使っています。なのでこちらを使用してもOKです。↩︎勘違いしないでいただきたいのですが,「マハラノビス距離の上位5%を除外するのが定番」ということではありません。例えば最初から「上位5%の人にフラグを立てよう」と決め打ちにしていると,もし100人中50人が適当回答者だったとしても,そのうち5人しか検出できないことになります。なので今回の基準はあくまでも授業の演習としてとりあえず除外を体験してみよう,というくらいの意味合いです。↩︎
psych::bfi.keysで確認可能です。変数名の頭にマイナスがついているものが逆転項目です。↩︎もちろん様々なパッケージにある関数も全て,どこかの誰かが必要にかられて
function()によって定義してくれたものなのです。↩︎実を言うと,
apply()なんか使わなくても7 - dat[,cols]で複数行まとめて処理は可能です。今回は自作関数の導入を兼ねてちょっと回りくどいやり方にしました。↩︎