Rで検索したら一番上
R, 多変量解析, 因子分析, 構造方程式モデリング, 項目反応理論, マルチレベルモデル
(公開版では省略しています。)
ここではRのインストールから,超基本的なRの使い方を説明します。といってもRの解説なんてものはネット上にゴロゴロ転がっているので,いろいろ見て試してみてください。
Rは,プログラミング言語の一種です。すごくシンプルに言うと超すごい関数電卓みたいなものです。「統計解析向け」とあるように,特にデータ分析で使われるような手法と相性が良い仕様を持っていたりするので,使いこなせると大抵の分析ができるようになります。
ちなみに統計解析にはRとPythonという二大勢力があります。どちらを使うのが良いか,という点については様々な要因が絡んできます。 主にPythonのほうが機械学習やディープラーニングといった領域には強かったり,アプリケーションへの組み込みがしやすいなどの理由のもあってか,就職して社会に出るのであれば圧倒的にPythonが良いとされています。 一方Rは,インタラクティブな分析とデータ可視化に大きなアドバンテージを持っています。そういった点から,最新の統計的手法を扱う学術研究の方面ではRのコミュニティのほうが活発な印象です。
誤解を恐れずざっくりいうと,理系はPython寄り,文系はR寄りであることが多いです。私の出身である心理学をはじめ,経済学や経営学でも研究者はRユーザーの方が多い気がします。 そんなわけで,神戸大学経営学部の経営データ特別学修プログラムでもRを使うことになりました。 ただ,できるならRもPythonも両方使えるようになっておくのが一番良いです(私はRしか使えませんが)1。
もうRは市民権を得ているので,Googleで検索するとたぶん一番上にR Projectのページが出てくるはずです。
Rで検索したら一番上
R Projectのページに行ったら,左の”Download”の”CRAN”というところをクリックします。
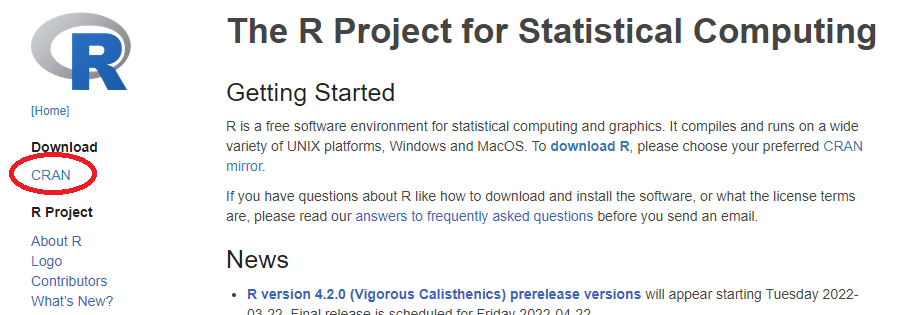
続いて,ミラーサイトを選択します。Rの本体およびパッケージ群は,Comprehensive R Archive Network (通称CRAN2)によって管理されています。CRANは世界各地にミラーサイトが用意されているため,なんやかんやDLする場合は近場のミラーサイトを選択するのが無難です。 …ですが最近ではとりあえず一番上のクラウドサーバーを選んでおけばOKという風潮があります。
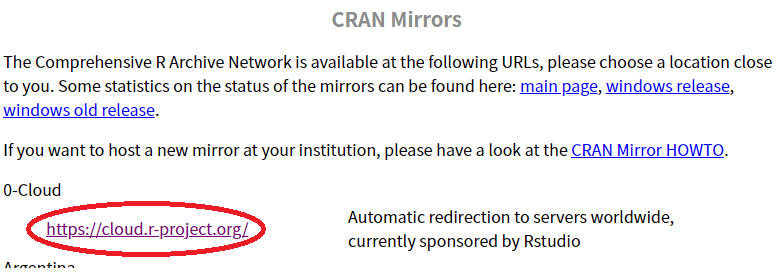
あとはご自分のパソコンのOSに合わせて選んでダウンロードしてインストールしたらOKです。
※Windowsユーザーの方は一番上の”base”を選んでください。
Rをインストールしたら起動してみましょう。とりあえずこれでRが使えるようになりました。簡単ですね。
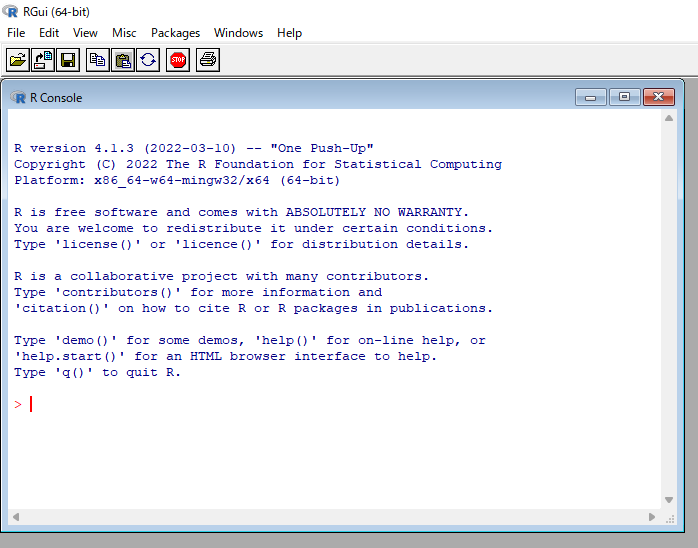
カーソルの左側が>となっているときには入力可能です。試しに1+1とかやってみてください。
Rは単体でも問題なく使えるのですが,もっと楽したいものです。
Rに限らずですが,プログラミング言語を扱う場合には,一つの画面でコードを書いたり実行したりなんやかんや…がまとまっている環境(統合開発環境: IDE)を用意しておくのがベターです。 RでいうとRStudioというものが最も有力です。 R単体で分析する場合にはRStudioがおすすめですが,pythonなどの別の言語と組み合わせて分析などする場合には他のエディタも候補に上がってきます3。
Positronとは,Rstudioの開発元であるPositが開発している新しいIDEです。 もともとMicrosoftが開発していたVisual Studio Code(VScode)をベースにしているため,Rstudioよりも多言語に対応しているのが特徴です。 例えば「LateXで論文を書きながら,Rで分析しながら,ちょっとしたメモはmarkdownで書きながら…」みたいな猛者にはPositron (あるいはそのもととなったVScode)が向いているかもしれません。
そして,PositronがRStudioに大きく勝っているポイントは,AIの活用がしやすいという点です。 RstudioもGitHub Copilotを呼び出したインライン提案(Next Edit Suggestions: NES)を使ったり,頑張ればチャットを組み込んだりもできるようなのですが,Positronのほうが明らかにいろいろなことができるような気がします。 というのも,PositronにはデフォルトでPositron Assistantというコーディングエージェントが搭載されており,設定さえできれば,指示を与えてファイルを自動で編集させたりコードレビューをさせたりができるようになるのです。 また,PositronのベースはVScodeであるため,Claude codeやCline, Roo codeなど,すでに幅広く使われているコーディングエージェントを拡張機能としてインストールして利用することも可能です。 もちろん,コーディングエージェントを使い倒すためには課金が必要となるのですが,大学等の教育機関に所属している学生(および教職員)はGitHub Educationというサービスを利用することで,最新モデルを含めてGitHub Copilotをある程度は無料で利用することができます。
ちなみにこのコラムを書いている2026年4月時点では,Posit AIというプランがベータ版として提供されており,これに加入すると,Rstudioの中でもコーディングエージェント的なことができるようになるようです。 ただPosit AIは月額20$と結構高いので,もしすでに他のサービスに課金している(あるいはGitHub Educationが使える)場合には,Positronのコーディングエージェントからそちらを呼び出したほうが良い気もします。
(ただ,Positronは絶賛開発中という位置づけなので,講義では安定版のRStudioを使うことにしています。Positronは個人の自由意志で利用してください。)
ここからはRの基本オブ基本の話です。 後ほどデータを読み込んで操作したりしていくわけですが,まずは何よりRそのものの基本的な操作方法およびいくつかの重要な概念を理解しておきましょう。
四則演算はだいたい思った通りに書けばOKです。 プログラミング言語では,一般的に掛け算はxのような見た目ではなく*と表されるところだけご注意ください。
とまあこんな感じです。私はちょっとした電卓代わりに使ったりもします。
プログラミング言語には「変数」と「関数」がよく出てきます。 数学で出てくる「変数」や「関数」と同じといえば同じですが微妙に異なる気もします。 一般的にプログラミング言語では「変数」と呼ばれるものは,Rではオブジェクトと呼ばれたりします。
オブジェクトとは,何らかの値を入れておく「ハコ」のようなものだと思ってください。 例えば,以下のコードではboxというハコに2という数字を入れています。
ハコの名前は基本何でも良いので,例えばhako <- 2としても問題ありません。 この場合はhakoという名前のハコに2という数字が入ります。 また,ハコの中に入るものはほぼなんでもOKです。この後いろいろ出てきますが,単一の数字の他にも,複数の数字のまとまり(ベクトル)や文字を入れることも可能です。 なおR言語では,ダブルクオート(" ")またはシングルクオート(' ')に挟まれたものは「文字」として扱われます(詳細はもう少し後で)。
では,以下のコードの答えはそれぞれ何になるでしょうか。
*は掛け算の記号でした。 そしてboxには2という数字が入っていたので,答えは6となります。 一方,box2には"hello"という文字列が入っています。文字を3倍することは(通常の方法では)できないので以下のようなエラーが返ってくるのです。
Error in box2 * 3: non-numeric argument to binary operatorちなみに上記のエラー文に出てくる単語はそれぞれ
non-numericは「数字じゃない(厳密に言うと,数字を表すnumeric型ではない)」argumentは「引数」binary operatorは「二項演算子」という意味です。二項演算子とは,例えば*や+のような「計算を表す記号」です。掛け算や足し算などは2つの数字(引数)を用いて行われる演算です。Rではこうした記号が表す演算はnon-numericな引数ではできません4。そのため「二項演算子の引数がnon-numericじゃあ駄目だよ」というエラーを出しているわけです。…というように,エラー文はちゃんと読むことができれば解決のヒントを教えてくれます。最初は専門用語などがあってわかりにくいと思いますが,頑張って慣れていきましょう。
Rにはベクトルというものもあります。更にいうと行列もあるのですが,それは後ほど紹介します。 とりあえずここでは簡単にベクトルの説明をしておきます。 数学で出てくるベクトルとは概ね異なるものですが,これはよく使うのでしっかり理解しておきましょう。 例えば,以下のコードではvecというハコ(オブジェクト)に2から10までの偶数が並んだベクトルを入れています。
ここでc()というのは,combineの略で,複数の値を一つのベクトルにまとめるための関数です。 関数については後ほど詳しく説明しますが,とりあえずは「c()の中に複数の値を入れると,それらをひとつにまとめてベクトルにしてくれる」と理解しておいてください。 重要なのは,複数の数字が1つのオブジェクトとしてまとめて扱えるという点です。
ではこのvecを,オブジェクトが単一の数字であったときと同じように3倍するとどうなるでしょうか。
ベクトルに四則演算を適用した場合,ベクトル内のすべての要素が3倍されます。ここは数学のベクトルと同じですね。したがって答えは6, 12, 18, 24, 30となるわけです。
ベクトルの中から特定の要素を取り出す場合には[ ](四角カッコ)で要素番号を指定してあげます。 例えば以下のコードでは,vecというオブジェクトの中にある3番目の要素を取り出します。
Rの中では,[ ]は基本的にいつでも「何番目の要素か」を表す記号(インデックス)です。そのため,先ほどからRの出力の左に毎回出ていた[1]というのは「ここから(出力の)1番目の要素ですよ」ということを意味しています。
実は[ ]の中身は数字である必要はありません。例えば先程作ったboxをそのまま入れると…
これはvecというベクトルの中のbox番目の要素を取り出します。boxには2という数字が入っていたので,上のコードはvec[2]と同じ動きをして,4を返しているわけです。
当然ですが,[ ]の中にベクトルの長さよりも大きな値や,そもそも数字では無いものが入っていた場合,NA (Not Available)という値が返ってきます。つまりは「そこに値は無いよ」という意味です。
では,マイナスの値が入っていた場合は?
実はこの場合,それ以外の要素が返ってきます。つまり上のコードではvecの中から3番目以外を返しているわけです。
では,ここまでの内容の復習も兼ねて,以下のコードを実行したらどうなるか頭の中でシミュレートしてみてください。答え合わせは手元のRで。
数学の関数は,例えば\(f(x)=x^2 + 5x + 6\)のようなものでした。もう少し説明すると,関数\(f\)は\(x\)という値が入ると\(x^2 + 5x + 6\)という計算結果を返す,そういうやつです。なので\(f(2)=20\)となるし,\(f(10)=156\)となります。 これはRを含む多くのプログラミングでも同じです。例えばsum()という関数は「すべての合計を返す」というものです5。多変数関数として数学っぽく書くなら\(\mathrm{sum}(x_1,x_2,x_3)=x_1 + x_2 + x_3\)ということです。 したがって,下のコードは\(\mathrm{sum}(x_1=1,x_2=3,x_3=5)=1+3+5\)を計算していることになります。
関数のメリットは入力の値が何であっても同じ作業をレシピ化できるという点です。sum()くらいならいちいち足しても良いのですが,もっと複雑になるといちいち書くのは面倒です。例えば1から10までのベクトルの不偏分散を計算する,というプロセスをsum()以外の関数を使わずに描くと
となります。与えられるデータvecが変わるたびにいちいちこれをやるのは面倒ですし,割り算の分母をきちんとvecの長さに応じて変える必要があり,明らかにヒューマンエラーが起こりそうです。
実はRには不偏分散を計算する関数としてvar()が用意されています。つまり上の処理はかんたんに
と書けるわけです6。
また関数は数値計算だけのものではありません。これまでに何度も登場してきたc()というものも関数ですが,これは単純に「与えられたものを全部くっつけてベクトルにする」という処理を行います7。くっつけるだけなので数値計算は行っていないですし,ベクトルの中に文字列を入れることもできます(Rのベクトルは数学のベクトルよりも広い概念なのです)。
なんでもありとは言え,実際にはベクトルの中身は,同じ性質のもの(数字だけ,文字列だけ)にしておくのが無難です。というのも,例えば上で定義したvec2に対してvec2 * 3のような計算を行おうとしても,文字列"Hello"のせいでエラーが返ってきてしまいます。
当然ですが,私も(たぶんこの世の誰も)Rのすべての関数が頭に入っているわけではありません。プログラミングはトライ&エラーを繰り返す世界なので,重要になるのはわからないときに調べる能力です8。
例えばある質問項目への4人の回答の平均値を計算する場面を考えてみます。オブジェクトans_q1に,4人の回答をベクトルとして代入しました。ただし,3番目の人はこの項目に無回答だったため,NAを入れています。 このベクトルに対して,平均値を計算するmean()関数を適用するとどうなるでしょうか。
実はmean()やsum()などの関数では,一つでもNAが入っているとNAを返す仕組みになっています。これ自体はRの挙動としてなんの問題もないのですが,回答した人での平均値を出したいとすると,少し手を加えてやる必要があります。 このように,特定の関数についてちょっと手を加えたい(e.g., 因子分析の因子数を変えたい,一般化線形モデルのリンク関数を変えたい)場合,まずは関数のヘルプを見てみましょう。関数のヘルプは以下のいずれかのコマンドで表示可能です。

mean()関数のヘルプ
ヘルプには,だいたい上から順に次のような内容が書かれています。
mean()関数にはmean(x, trim = 0, na.rm = FALSE, ...)と書かれています。このカンマで区切られた一つ一つ(x, trim, na.rm)を引数(ひきすう)と呼び,trim = 0とは「trimを指定しなかったらデフォルトで0を入れておくよ」ということを意味します。反対にxにはデフォルトの値がありません。当然ですがmean()関数は引数xの平均値を返すわけなので,xがなければ動きようが無いわけです。
mean()関数には無いですが,Details欄にはその関数について細かい説明が書かれていることがあります。Argumentsについても細かい説明をしてくれている事があるので,マジでわからないときはここまで読んでみてください。
mean()に対しては,加重平均をとるweighted.mean()や,行列の列ごとの平均を取るcolMeans()などがあります。
ということで,関数のヘルプを見た結果,以下のようにすると正しく回答した3人の平均値が得られることがわかりました。
料理をする場合,工夫次第では包丁とフライパンさえあれば結構いろいろなことができるようになります。ですが,じゃがいもの皮を剥く場合には包丁よりもピーラーのほうが楽と感じる人が多いでしょう。ピーラーは皮むきに特化した調理器具なわけです。
これと同じように,デフォルトのRは基本的な関数だけしか入っていない最小構成になっています。といっても結構いろいろなことができるわけですが,やはり高度な分析(e.g., SEM,項目反応理論)になるとそのままでは厳しくなってしまいます。Rにはパッケージと呼ばれる拡張機能のようなものが大量にあります。最後にパッケージの説明をして,Rの基礎レクチャーは終わりにします。
ここでは,因子分析のときにお世話になるpsychパッケージを入れてみましょう。psychはその名がなんとなく示すように,心理学にまつわる統計解析で便利な関数がいろいろ入っています。パッケージは,R本体と同じようにCRANからダウンロードしてインストールするので,インターネットにつながった状態で以下のコードを実行してください。
ここで注意するのは,引数はクオートでくくった"psych"にするという点です。Rでは,シングルクオート(' ')またはダブルクオート(" ")でくくられたものは文字列(character型)として扱われるのですが,install.packages()関数が正しく解釈できる引数はこのcharacter型の場合のみです。もしも引数をくくらずにinstall.packages(psych)とした場合,install.packages()関数はpsychというオブジェクト(ハコ)を探しに行ってしまいます。すると,「psychなんてハコはまだ無いよ」とエラーが返ってきてしまいます9。
出力画面にError:で始まる何かが表示されずに入力画面の左が>に戻ればインストール成功です。パッケージのインストールは「ピーラーを買ってきた」状態なので,実際に使うためには「ピーラーを棚から出す」手続きが必要になります。
install.packages()関数では,ネットワーク上からパッケージのファイルをダウンロードして,Rが呼び出せるように準備を整えてくれます。 このとき,ダウンロードされたパッケージのファイルは,パソコンの(ローカル)フォルダの中に格納されます。
フォルダの場所はOSおよびRのインストール時の設定等によって変わるため一概には言えませんが,例えばWindowsのPCで,インストール時の設定を弄らなかった場合には,C:\Program Files\R\R-x.y.z\libraryというフォルダ(x.y.zはRのバージョンの数字)の中に,パッケージごとにフォルダが置かれているかと思います。
パッケージが(ローカル)フォルダ内に保存されるということは,基本的に同じパッケージに対して毎回install.packages()を実行する必要は無いですし,install.packages()のとき以外にはRがネットワークに繋がっている必要もありません。 つまりこの直後に紹介しているlibrary()関数から始めて大丈夫です。
ただし,フォルダのパスにx.y.z(Rのバージョンの数字)が入っているように,Rのバージョンが変わると,基本的にパッケージは全て入れ直す必要があるという点だけはご注意ください。
パッケージの呼び出しはlibrary()関数を使います。この手続きはRを起動するたびに行う必要があるので注意してください。 パッケージを呼び出しせずにパッケージ内の関数を使おうとすると,ほとんどの場合では以下のようなエラーが返ってきます。このときには関数名を間違えていないか,パッケージをちゃんと呼び出したかを確認してください10。
ここからは,R上でデータを操作するために必要な基本操作を紹介していきます。 まずはデータを読み込んでいきましょう。
本講義では,特に断りがない限りコードやデータなどは全てワーキングディレクトリに置かれている前提でコードを示します。
(↑この意味がわかった人はこのセクションは読み飛ばしてOKです。しばし休憩しててください。)
パソコンでは,全てのファイルはどこかしらのディレクトリ (directory)に置かれることになります。いわゆる「フォルダ」というものも,一つのディレクトリを表したものと考えることが出来ます。ディレクトリはファイルの「住所」のようなもので,例えば私(Bunji)のWindowsのデスクトップにhogehoge.xlsxというExcelファイルが置かれていたとすると,実際にはC:/Users/Bunji/Desktop/hogehoge.xlsxという位置づけになっています11。つまり,例えばExcelなどでhogehoge.xlsxを開こうとした場合,厳密には「C:/Users/Bunji/Desktop/hogehoge.xlsxを開け」という指示が出されているわけです。
ちなみにディレクトリはスラッシュ(/)で階層構造を表しています。つまり先程のhogehoge.xlsxはC:の中のUsersフォルダの中のBunjiフォルダの中のDesktopフォルダの中にある,ということが示されています。
【結論を先にいうと】スラッシュ(/)の代わりにバックスラッシュ(\)を使う場合は,2つ連続して使用(\\)してください。
階層構造を表す記号として,スラッシュ(/)の代わりにバックスラッシュ(\)や¥マークが使われることもあります。
ただし,実はバックスラッシュと¥マークは本質的には同じ意味を持っています。たぶんパソコンの環境や使用するソフトウェアによっては,キーボードの¥マークが書かれたキーを押してもバックスラッシュが表示されたりするでしょう。
そしてディレクトリの階層構造を表す場合,スラッシュでもバックスラッシュでもどちらでも良いのですが,バックスラッシュをする場合,プログラミング言語には「エスケープシーケンス」と呼ばれるちょっと厄介な事情があります。 プログラミング言語の多くでは文字列を扱うことができますが,文字列には「文字で表せない文字」とでも呼べるような存在があります。例えば改行なんかがその代表例です。改行を含む以下の文字列を考えてみます。
I am
happy.
当然改行自体は文字として表せないのですが,プログラミング言語の中で扱うためには改行も含めて一つの「文字列」として扱わないと,改行の無い”I am happy.”と区別ができなくなってしまいます。そこで多くのプログラミング言語では,このような「文字で表せない文字」を表す特殊な文字が用意されています。例えば改行を表す特殊文字は\n(バックスラッシュ+n)です。したがって,改行ありは"I am \nhappy."と表すことで,改行なし("I am happy.")と区別ができるわけです。ちなみにRではcat()関数を使うと,特殊文字を変換した後の文字列を表示することができます。
ここでの問題は,バックスラッシュが通常は「次の文字が特殊文字であることを表すための記号」として扱われるということです。ではここで,先程出てきたディレクトリをバックスラッシュに置き換えたバージョンを見てみます。
C:\Users\Bunji\Desktop\hogehoge.xlsx
このとき,ディレクトリを前から順に解釈しようとすると,\が登場した瞬間に「次に来る文字は特殊文字を表しているな」と解釈しようとします。したがって,\Uや\Bといった特殊文字として解釈しようとするわけです。そしてそんな特殊文字はRには用意されていません。 そんなわけで,/と\の違いによって
C:/Users/Bunji/Desktop/hogehoge.xlsxを開け→問題なく開けるC:\Users\Bunji\Desktop\hogehoge.xlsxを開け→「\Uなんて特殊文字は無い」とエラーが出るというように結果に違いが出てしまいます。このエラーを避けるためには,「この\は特殊文字を表すバックスラッシュではなくただのバックスラッシュである」ということを示すために「バックスラッシュを表す特殊文字」を使います。具体的には,バックスラッシュを2つ重ねた\\が「ただの文字としてのバックスラッシュ」を表すので,
C:\\Users\\Bunji\\Desktop\\hogehoge.xlsxを開けという指示であればスラッシュのときと同じように機能してくれるわけです。
「ファイルを開く」ときの指定方法はもちろんRでも同じです。つまりRでhogehoge.xlsxを開こうとした場合,通常は「C:/Users/Bunji/Desktop/hogehoge.xlsxを開け」という指示を出す必要があります。 ですが,Rを始めとするプログラミング言語(というかほとんどのプログラム)では,ファイルの位置を相対的なものとしても考えることができます。その時の基準となるディレクトリのことを,Rではワーキングディレクトリと呼んでいます。 例えばいま,ワーキングディレクトリがC:/Users/Bunji/Desktop/に設定されているとします。このとき,hogehoge.xlsxというファイルを読もうとすると,「(このディレクトリにある)hogehoge.xlsxを開け」だけで通じるようになるのです。 もう少し正確に言うと「C:/から始まる絶対パスが指定されている場合にはそのファイルを,そうではなく相対パスが指定されている場合には,ワーキングディレクトリ内のそのファイルを開け」という感じになっており,ファイルの指定方法は2種類ある,ということになります。
Rで現在のワーキングディレクトリを確認および変更する方法はそれぞれ以下のとおりです。
たぶん.RファイルなどをクリックしてRstudioを開いた場合,デフォルトでは「起動時のワーキングディレクトリはその.Rファイルなどがある場所」になると思います。この先で「あるはずのファイルが読み込めない」という事態に陥った場合は,まずgetwd()でワーキングディレクトリの設定を確認し,必要に応じてsetwd()で変更してください。
ということで,この講義で使用するファイル一式を格納するフォルダを用意しておき,使用するデータやこの先作成するコードは全てそのフォルダ内に入れるようにしておきましょう。そして,ワーキングディレクトリとしてそのフォルダを指定するようにしましょう。
…と,ここまでの話がよくわからなかった人も安心してください。 Rstudioにはそういった面倒事を避けるための機能としてプロジェクト(Project)というものが用意されています。 Rstudioを用いて分析を行う場合には,とりあえず何も考えずにプロジェクトを作成するクセを付けておくと良いかもしれません。
RStudioのプロジェクトは,半透明の立方体にRと書かれたアイコン( 図 1.7 )で表されます。まずはRStudioのたぶん左上の方にあるこのアイコンを探してください。
あるいは「File > New Project」でも構いません。
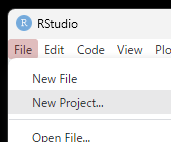
続いて,プロジェクト用フォルダをどこに作成するかを決めます。 図 1.10 には “New Directory” と “Existing Directory”,あと一つなんかありますが,とりあえず上の2つのいずれかから選びましょう。
新しくフォルダを作成して,そこをプロジェクト用フォルダとする。これから作業を始めるのでまだデータを置く場所も何も決まっていない場合はこちら。
既存のフォルダをプロジェクト用フォルダとして利用する。すでにデータや原稿などを一つのフォルダにまとめていて,そのフォルダにRのコードも一緒に置いておきたい場合はこちら。
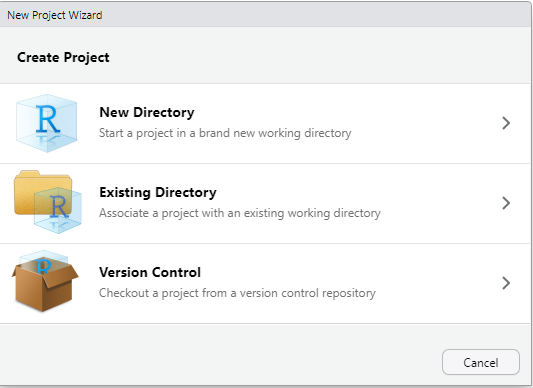
いろいろな”Project Type”から一つ選べと言われます(図 1.11)。 Rを使いこなせるようになると,Rを使って本を書いたり(Quartoやbookdown),自分でパッケージを作れるようになるので,それ用の設定が色々と用意されているわけですが,単純に分析だけする場合には一番上の”New Project”を選べばOKです。
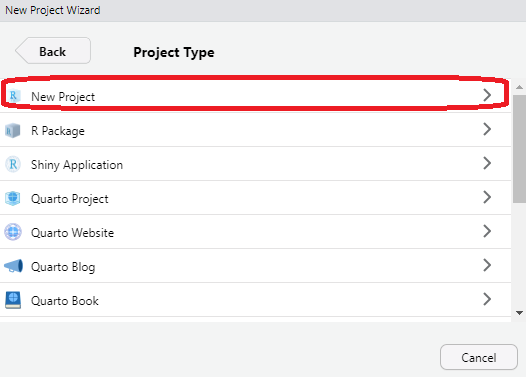
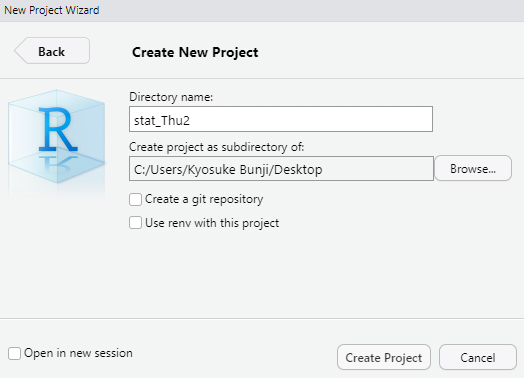
あとは新規プロジェクトフォルダの作成場所を決めるだけです。 “Directory name”にはプロジェクトの名前を(自分でその意味がわかるようにしておけばOK),“Create project …”にはどこのフォルダにそのプロジェクトを置くかを指定してあげます。 つまり 図 1.12 のように指定した場合には,C:/Users/Kyosuke Bunji/Desktopにstat_Thu2というフォルダが新規に作成され,そこがプロジェクト用フォルダとして利用可能になっているわけです。
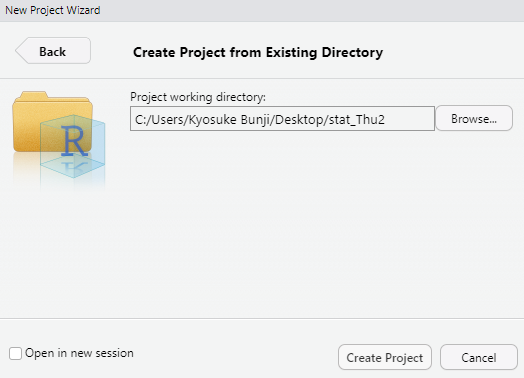
こちらの場合は,どのフォルダをプロジェクト用フォルダにするかを指定するだけです。 図 1.13 のように指定した場合には,C:/Users/Kyosuke Bunji/Desktop/stat_Thu2 というフォルダがプロジェクト用フォルダになるわけです。
プロジェクトの作成が完了すると,フォルダ内に(プロジェクト名).Rprojというファイルが作成されているはずです。 今後データなどは,この.Rprojと同じところに入れていくようにしておけばOKです。 また,Rstudioを開く場合には.Rprojファイルをダブルクリックなどして開くようにしてください。
紙で実施した場合でもWebで実施した場合でも,収集したデータはRで読み込めるように準備してあげる必要があります。 データの形式は,基本的にはCSV (Comma Separated Values)にしておけば問題ありません。 Excelで入力を行い,保存するときにファイル形式を.csvに指定しておきましょう。 もちろんCSV以外の形式(.xlsxや.txtなど)でも読み込みは可能です。 ですが一般的に,1行1レコードで各列が一つの変数を表すマトリクス形式のデータの場合,CSVがデファクトスタンダードな気がします。
まず大前提として,CSVは実は普通のテキストファイルです。 実際に普通のメモ帳(Macならテキストエディット)で.csvファイルを開いてみるとよくわかります。
一般的に,データというのは縦横に並んだ(Excelの画面のような)形をしています。 「ならばExcelのファイル(.xlsx)でもいいじゃん」と思われるかもしれませんが,.xlsxファイルにはMicrosoft Excel(あるいは互換性のあるソフトウェア)がないと開けないという問題があります。 今どきみんなExcelくらい持っているだろうというのは驕りです。 例えばExcelのバージョンが異なると,同じファイルが同じように開けないかもしれません。
そこで,縦横に並んだデータ形式を特定のソフトウェアに頼らない(パソコンがあれば誰でも使える)形で表そうとして定められた特殊ルールの一つがCSVなのです。 テキストファイルの拡張子を.csvとすると,CSVの名の通り,Excelで言うところの各セルの区切りをカンマ(,)によって表していると解釈する決まりになっています。 例えば
ID,年齢,性別,身長,体重
1,20,男,168,64
2,,女,158,
3,39,男,178,79というテキストファイル("data.txt")があったとすると,これ自体はただの(カンマがたくさんある)テキストです。 しかし,これをCSVファイルとして扱うことを宣言する(ファイル名を"data.csv"にする)と,ファイル内のカンマが「セルの区切り」を意味するものと解釈され,表 1.1 のような構造をしたデータであると認識できるようになるのです。
| ID | 年齢 | 性別 | 身長 | 体重 | |
|---|---|---|---|---|---|
| 1 | 20 | 男 | 168 | 64 | |
| 2 | 女 | 158 | |||
| 3 | 39 | 男 | 178 | 79 |
ということで,CSVファイルがデファクトスタンダードになっている理由を一言で言えば「最も高い確率で誰の環境でも同じように開くことができるため」と言える気がします。
本講義では,事前に用意したdata.csvというファイルを使用するので,早速これを読み込みましょう。
xlsxファイルを読み込むための関数は,デフォルトでは用意されていません。よく使われるのは,readxlパッケージにあるread_xlsx()という関数です。ちなみにRstudioならば左上のFile→ Import Dataset→ From Excel…からでも読み込みが可能です。というかread_xlsx()関数が使えます。
(ただ,エクセルファイルの場合にはセル内改行やセル結合などがあって厄介なことが多いので気をつけてください…)
このように,結構いろいろなファイル形式のもの(SPSSとかSTATAとかSASとかも)を読み込むための関数が様々なパッケージで用意されているので,そういったファイル形式のデータを読み込みたい場合には,まずは検索してみてください。
今回使用するデータは,psychパッケージの中にあるサンプルデータbfiをちょっと加工したものです。ということでここでbfiデータの説明をしておきます。
このデータは,オンラインで行われている大規模調査 SAPA (Synthetic Aperture Personality Assessment) Project のデータの一部です。このプロジェクトでは世の中にある大量のパーソナリティ測定のための項目を集めて,大規模な項目セット(International Personality Item Pool)を作成したりしています。使用している尺度および項目の理論的背景には,心理学では有名なビッグファイブ Goldberg (1993) というものがあります。すごくざっくり説明すると「人間の性格特性は5つの次元に分類できる・5つの次元で説明できる」というものです。5つの次元は,文献によってちょこちょこ名前が変わったりするのですが,基本的には 表 1.2 のものになります(説明はWikipediaより)。
| 次元 | 説明 |
|---|---|
| 協調性(Agreeableness) | 社会的調和に対する一般的関心における個人差を反映する。協調性がある人物は,他人とうまくやっていくことを大切にする。 |
| 誠実性(Conscientiousness) | 組織化され信頼できる傾向,自己コントロール能力を示す傾向,忠実に行動する傾向,達成を目指す傾向,自発的な行動よりも計画的な行動を好む傾向を表している。 |
| 外向性(Extraversion) | 活力,興奮,自己主張,社交性,他人との付き合いで刺激を求める,おしゃべりであることを表している。 |
| 神経症傾向(Neuroticism) | 怒り,不安,抑うつなどの否定的な感情を経験する傾向のことである。 |
| 開放性(Openness) | 芸術,感情,冒険,珍しいアイディア,想像力,好奇心,および多様な経験に対する一般的な評価である。 |
ということで,データの中には 表 1.3 に示す変数が含まれています。
data.csvの変数
| 変数名 | 説明 |
|---|---|
ID |
整理番号(元データには無いですが追加しました) |
Q1_1からQ1_25 |
心理尺度の項目(全25項目) |
gender |
性別(1=男性, 2=女性) |
education |
最終学歴(1=高校中退,2=高卒,3=大学中退,4=大卒,5=大学院卒) |
age |
年齢 |
心理尺度の項目は,前から順にそれぞれ5項目ずつ,協調性,誠実性,外向性,神経症傾向,開放性を表す項目になっています(具体的な項目は?psych::bfiでヘルプを参照)。 ビッグファイブの細かい理論的なことはともかく,今後の分析の上では「5項目×5因子の心理尺度」と「性別・最終学歴・年齢」という変数があるということだけ理解しておいてください。 そして,このデータだけを使って無理やり全ての分析を紹介するので,結果の解釈などに多少の無理があることはご了承下さい…。
これ以降は,Rの操作の最低限を速習していきます。 なお,Chapter 2から4では,いろいろなデータの前処理をしながらRの操作に少しずつ慣れていくコースです。 そのため,データにはちょくちょくおかしなポイントがありますが無視して進みます。 余裕があれば一つ一つ追いかけながら試してみるとよりRの知識が高まるかもしれません。
(なお本Chapterの最後に,Chapter 2から4の手順を経たあとの「きれいな」データを用意しているため,これらをすっ飛ばしてChapter 5に行くことも可能です。)
flowchart TD
%% 上段: 現在位置
current["第1章<br/>(ここまで読了)"]
%% 選択肢を横並びにするサブグラフ
subgraph choices[" "]
direction LR
path1["第1章の残りを<br/>そのまま読み進める"]
path2["第1章は<br/>ここで終わり"]
end
%% 後続章
chap2["第2章<br/>データの準備"]
chap3["第3章<br/>データの前処理"]
chap4["第4章<br/>予備的分析"]
chap5["第5章<br/>回帰分析のおさらい"]
current -->|"前処理から<br/>しっかり抑える"| path2
current -->|"すぐに分析手法を<br/>学ぶ"| path1
path1 -.-> chap5
path2 --> chap2
chap2 --> chap3
chap3 --> chap4
chap4 --> chap5
style choices fill:#ffffff00,stroke:#ffffff00
データを読み込んだら,まずは正しく読み込めているかをざっと確認します。 確認の方法はRユーザーの数だけ存在すると思いますが,head(),str(),summary(),View()なんかが良く使われるベーシックな関数ではないか,と思います。 とりあえず試してみましょう。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
1 1 2 4 3 4 4 2 3 3 4 4
2 2 2 4 5 2 5 5 4 4 3 4
3 3 5 4 5 4 4 4 5 4 2 5
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
1 3 3 3 4 4 3 4 2 2
2 1 1 6 4 3 3 3 3 5
3 2 4 4 4 5 4 5 4 2
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1 3 3 6 3 4 3 1 -99 16
2 5 4 2 4 3 3 2 -99 18
3 3 4 2 5 5 2 2 -99 17
[ reached 'max' / getOption("max.print") -- omitted 3 rows ]head()は「とりあえず読み込めているか」の確認程度には使えます。また,データの前処理・加工の過程でも,ちょくちょくhead()をすることで「今のところうまく行っているか」を確認したりにも使います。 データが読み込めたら,列の名前や入力されている値が想定通りになっているかを確認しましょう。
学部の統計学の講義では,最初に変数のタイプのお話をすることが多いです。みなさんが受けてきた講義がどうだったかは分かりませんが,私の講義ではそのようにしています。 変数のタイプとは,例えば「量的変数と質的変数」だとか「連続変数と離散変数」「間隔尺度やら順序尺度やら」などといった言い方で分類されるものです。 統計学において変数のタイプ分けがなぜ重要だったかというと,タイプごとにできる計算・分析が異なるためでした。 datの中身で言えば,最初の行のIDは見た目は数字ですが,個人を識別するための名義尺度(=質的変数)なので,例えば「IDの平均値」を計算しても何の意味もありません。 重要なのは,変数のタイプは見た目では判断できないということです。IDはその後ろの回答データQ1_1以降とは明らかに違う型なのですが,特に最初の数行を見ただけでは区別はできません。 そこで,R言語(というか多くのプログラミング言語)でこうしたデータを扱う場合には,データの中身(具体的な値)と変数の型をセットにして管理していくことになります。
R言語では,結構いろいろなタイプのデータ・変数を扱うための「型」が用意されています。とりあえずデータ分析の範囲で登場する代表的な型としては以下のようなものがあります。
| 型名 | 説明 |
|---|---|
integer |
整数 |
numeric |
実数(整数+小数) |
character |
文字列 |
factor |
順序なし因子(名義変数などで使用する) |
ordered |
順序つき因子(リッカート尺度にも使う) |
logical |
TRUEとFALSEだけ |
少し前に説明したように,R言語では" "または' 'で括られたものはcharacter型の変数となります。 例えば同じ「3」という表記でも,3はinteger型なので四則演算に使える一方,クオートで括られた"3"はcharacter型,つまり「3」という文字として扱われるので,これに別の数字を足し合わせること(例えば"3" + 2など)は出来ません。また,この後出てくる分析の方法のいくつかでは,この型の違いによって処理結果が変わることがあります。 なので変数の型については多少知っておくことで,思った通りの分析結果が出なかったときの原因の一つとして考えられるようになると思います。
また,表 1.4 に載っている型はあくまでも単一の変数の値についてのものです。 一方で,複数の値がくっついたベクトルはvector型のオブジェクトと呼ばれます。 例えばvec <- c(2, 4, 6, 8, 10)として作られたvecは,「中に5つのinteger型の変数(オブジェクト)を持っているvector型のオブジェクト」というわけです。 このように,オブジェクトの構造などを示すための「型」というものも大量に存在しています。 普通に分析をする中で意識することはあまり多くないのですが,一部の関数では,引数で与えるオブジェクトの型によって挙動が変わるものがあるので,思った通りの分析結果が出なかったときには型に注意してみると良いかもしれません。
Rに限らずほぼすべてのプログラミング言語では,異なる変数のタイプを表すための「型」という概念が用意されています。 それぞれの言語がどのような型を用意しているかは,その言語が何を目的として作られたかによって変わってきます。 R言語は,特に統計解析に特化した言語なので,他の言語ではほぼ見られないfactor型やordered型といった「変数の実質的な意味」による分類の型が用意されています。
統計解析をしない言語であっても「型」の概念は存在しているわけですが,その理由の多くは「安全性」と「効率」だと思っています。 プログラミング言語が使われる場面では,「絶対にエラーを吐いて停止してはいけない」とか「できるだけ大量のデータを高速でさばきたい」といったことが求められがちです。 そこで「想定していない型の変数が来たらそもそも処理を行わない」とか「変数の型によって異なる処理を用意する」としておくことで,思わぬエラー(例えば文字列の足し算をしようとしてしまう)を防ぐことができます。
また,変数の型を明示しておくことでメモリの節約や処理速度の向上も見込まれます。 例えばRでx <- 3という感じで変数を定義する場合,特にその変数の型を指定していませんが,中身(3)から,integer型だろうと推察してくれます。 実はinteger型はどこまでも大きな値を取れるわけではなく,-2147483647から2147483647までの整数しかいれることができません。 これは,32ビットの2進数で表せる値の限界です。2進数で”1111111111111111111111111111111”(1が31個)と表される数が2147483647なのです。 つまり,Rでx <- 3という指示を出した場合,変数xの値を保存するために,2進数では0000000000000000000000000000011として記録することで,仮に2147483647が入っても問題ないようにしています。なんだかもったいないですよね。 一個だけなら良いのですが,datは2800人分のデータなので,一つのinteger型の変数ごとに\(2800\times31\)個のビット(01)が使われているわけです。 これは,もっと大規模なデータを処理する必要のある環境では結構な問題になってしまいます。 例えばdatの中のQ1_1は1から6しか取らないとわかっているので,2進数で表記するためにはビットが3つ(001, 010, 011, 100, 101, 110)あれば十分です。
ということでプログラミング言語によっては,このような場合に備えて異なる長さのinteger型が用意されていたりします。確保するメモリを必要最小限にすることで,より多くのデータを処理できたり,処理速度の向上が見込めるわけです。 そしてそこまで厳密な言語では,変数を宣言する際に例えばint x = 3;という感じで,最初に変数の型を明示的に指定しておくことが求められます(静的型付け言語)。そしてその後に異なる型の値(上の例で言えば小数や文字列など)が入れないよう型にロックをかけてしまいます。 これに対してR言語では実際に入力された値に応じて勝手に変数の型を予測し,また異なる型の値が入る際には柔軟に型を変えてくれます(動的型付け言語)。
動的型付け言語のほうがいちいち変数の型を意識しなくても「いい感じに」処理をしてくれるというメリットがありますが,一方でいつの間にか想定と違う型になっていたりして処理に失敗するようなケースも出てきてしまいます。R言語を利用する際は,変数の型に結構注意する必要がありそうです。
では,実際にdatの中の各変数の型がどのように設定されているかを見てみましょう。自分で設定した覚えが無くても,R言語の中で扱う以上は必ずなんらかの型が勝手に設定されているのです。
'data.frame': 2800 obs. of 29 variables:
$ ID : int 1 2 3 4 5 6 7 8 9 10 ...
$ Q1_1 : int 2 2 5 4 2 6 2 4 4 2 ...
$ Q1_2 : int 4 4 4 4 3 6 5 3 3 5 ...
$ Q1_3 : int 3 5 5 6 3 5 5 1 6 6 ...
$ Q1_4 : int 4 2 4 5 4 6 3 5 3 6 ...
$ Q1_5 : int 4 5 4 5 5 5 5 1 3 5 ...
$ Q1_6 : int 2 5 4 4 4 6 5 3 6 6 ...
$ Q1_7 : int 3 4 5 4 4 6 4 2 6 5 ...
$ Q1_8 : int 3 4 4 3 5 6 4 4 3 6 ...
$ Q1_9 : int 4 3 2 5 3 1 2 2 4 2 ...
$ Q1_10 : int 4 4 5 5 2 3 3 4 5 1 ...
$ Q1_11 : int 3 1 2 5 2 2 4 3 5 2 ...
$ Q1_12 : chr "3" "1" "4" "3" ...
$ Q1_13 : int 3 6 4 4 5 6 4 4 -99 4 ...
$ Q1_14 : int 4 4 4 4 4 5 5 2 4 5 ...
$ Q1_15 : int 4 3 5 4 5 6 5 1 3 5 ...
$ Q1_16 : int 3 3 4 2 2 3 1 6 5 5 ...
$ Q1_17 : int 4 3 5 5 3 5 2 3 5 5 ...
$ Q1_18 : int 2 3 4 2 4 2 2 2 2 5 ...
$ Q1_19 : int 2 5 2 4 4 2 1 6 3 2 ...
$ Q1_20 : int 3 5 3 1 3 3 1 4 3 4 ...
$ Q1_21 : int 3 4 4 3 3 4 5 3 6 5 ...
$ Q1_22 : int 6 2 2 3 3 3 2 2 6 1 ...
$ Q1_23 : int 3 4 5 4 4 5 5 4 6 5 ...
$ Q1_24 : int 4 3 5 3 3 6 6 5 6 5 ...
$ Q1_25 : int 3 3 2 5 3 1 1 3 1 2 ...
$ gender : int 1 2 2 2 1 2 1 1 1 2 ...
$ education: int -99 -99 -99 -99 -99 3 -99 2 1 -99 ...
$ age : num 16 18 17 17 17 21 18 19 19 17 ...read.csv()関数を始めとするデータ読み込み系の関数では,各変数(列)の型を,その中身から推測して自動的に決定してくれます。この時,以下のような規則に従って型が決定されます。基本的には,型に合わない値(e.g., integer型なのに文字列が入っている)があるとエラーを起こしかねないので「読み込んだデータの中にある全ての値を取りうる型」に決定されます。つまり,
integer型と考えるのが妥当integer型だと困るのでnumeric型とみなす12。numeric型でも困るのでcharacter型とみなす。ということです。character型は単なる文字列なので,基本的にはあらゆる表記が許されます。
変数名の左のintは「この変数がint型である」ということを意味しています。intとはinteger型のことです。Rの処理の上では,整数か小数かはあまり重要ではありませんが,転記ミスを検出する上では役に立つでしょう。今回のデータの場合,一番下のageは年齢を表す変数なので整数しか入力されていないはずですが,intではなくnum (numeric型)と表示されています。つまり,どうやら変数ageには小数が入っている,ということらしいので,後で探して修正しましょう。また,Q1_12はchr (character型)になっています。ということは,Q1_12のどこかに数字でもない何かが入っている,ということです。必要に応じて修正しないといけません(が,ここでは無視して進みます)。
どこかから拾ってきたデータや,オンライン調査で自動的に記録されたデータを分析に使用する場合は,面倒でもR上で処理するようにして,その記録をコードとして残しておくべきと考えます。 というのも,そのようなデータについて(Excelなどで開いて)手作業で修正をしてしまうと,
といった問題が生じてしまいます。
一方で,もしもデータが自分で集めて自分で入力したものであれば,修正はR上よりもローデータをいじったほうが早いかもしれません。
read.csv()関数で読み込んだデータは,Rの中ではdata.frameという型13のオブジェクトとして扱われます。読み込んだ時点でそうなっているので普段は気にすることも無いのですが,中身をいじるときには多少その仕組みを知っておいたほうが良いと思います。
データフレームは,表向きには1行1レコードで各列がそれぞれ異なる変数を表す,いわゆる普通の(2次元)データの形式をとっています。ですが内部的には「列の集合」として扱われています。つまり,今回使用するデータで言えば, 図 1.15 のように複数の列があり,これらをまとめたものを「データフレーム」と呼んでいるわけです。このおかげで,列ごとに異なる変数型をとっても良い(numericとcharacterの混在)わけです。一方同じ2次元データでも,行列の型(matrix)の場合,線形代数などの演算を行うために,全ての値は同じ型でなければならないといった決まりがあります。
データフレームの要素(中身)を取り出す時には,[ ]という記号を使用します。前半ではベクトルの要素を取り出す方法として同じ記号を紹介しましたが,全く同じことです。 データフレームは表向きには2次元データ(行列と同じ)なので,例えば「i行j列目の要素を取り出したい」というときにはdat[i,j]としてあげましょう。 つまり[ ]の中に行番号と列番号をそれぞれ入れてあげれば良いわけです。行番号と列番号は複数個入れても良いので,ベクトルのときと同じように,以下のようなことも可能です。
ちなみに,行番号または列番号のいずれか一方だけを指定した場合には,指定されなかったほうは全て抽出されます。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
1 1 2 4 3 4 4 2 3 3 4 4
2 2 2 4 5 2 5 5 4 4 3 4
3 3 5 4 5 4 4 4 5 4 2 5
4 4 4 4 6 5 5 4 4 3 5 5
5 5 2 3 3 4 5 4 4 5 3 2
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
1 3 3 3 4 4 3 4 2 2
2 1 1 6 4 3 3 3 3 5
3 2 4 4 4 5 4 5 4 2
4 5 3 4 4 4 2 5 2 4
5 2 2 5 4 5 2 3 4 4
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1 3 3 6 3 4 3 1 -99 16
2 5 4 2 4 3 3 2 -99 18
3 3 4 2 5 5 2 2 -99 17
4 1 3 3 4 3 5 2 -99 17
5 3 3 3 4 3 3 1 -99 17結果の出力の形が今までとぜんぜん違うように見えますが,これは長いベクトルを表しています。一番左の[28]は「その行が28番目の要素から始まっているよ」という意味なので,例えば60番目の人の値を見たければ,[55]から始まる行の左から6番目を見ればよいわけです。
ちなみに,ベクトルと同じようにカンマを使わずに要素を指定したらどうなるでしょうか。つまり先程の最後のコードをdat[,27]ではなくdat[27]としたら?
データフレームの場合,カンマがなければ要素番号はそのまま列番号を指定したものとみなされます。これは 図 1.15 に示したように,データフレームが「列の集合」だからです。あるいは「列のベクトル」という言い方でも良いかもしれません。つまりdat[27]はdatの中にある「27番目のベクトル」を指示しているわけです。ただ,matrix型ではこのようには機能しないため,混乱を避けるためにも,常に明示的にカンマを入れておくことをおすすめします。
さて,ここまで行番号および列番号を用いてデータフレームの要素を抽出してきました。ですが,このように番号で指定するのはあまり良い方法ではないという意見もあります。それは,たとえば後からデータが追加された場合に古いコードが思わぬ挙動をしたり,後からコードを見たときに「なぜ27列目を指定したのか?」といった情報がなくなってしまうためです。ということで,可能な限り列の指定に関しては列名を用いて行うことをおすすめします。
データフレームの場合,列の指定の方法がいくつかあります。上の例では,カンマを省略した場合だけ縦に表示されました。通常,データフレームや行列から1行または1列だけを取り出すと,取り出された要素は1次元になるため,ベクトルとして扱われる(出力が横に並ぶ)ようになります。なのですが,カンマを省略した場合だけは「1列のデータフレーム」として扱われるという挙動になっています。もしも今後みなさんが使用する関数で「データフレーム型しか受け付けない,ベクトルはダメ」という関数があった場合は,データフレーム型のままにしておく必要があるかもしれません。
ただ,「カンマを省略すると1列のデータフレームになる」と言うのはあくまでもデータフレーム型特有の挙動なので,こんな細かいことをいちいち覚えているのはあまり効率的ではありません。そこで(かなりマニアックな)別の方法をお教えします。それはdrop=FALSEという引数を使う方法です。
1行または1列だけを取り出したときにベクトルに型変換される,というのは,複数行・列が無いためにデータフレームの型を保てず,結果的にベクトル型に落ちた,という見方が出来ます。その「落ちた」をおさえるのがdrop=FALSEです。
使用する際には, 上記のように,列番号の後にdrop=FALSEを指定してあげると,カンマを省略したdat["gender"]と同じ結果が得られます。
列を指定する際は番号ではなく列名で行う,という話をしましたが,行のほうはどうしましょうか。行には名前はありません。行にも列にも(ベクトルでも)使える別の指定方法がlogical型で指定するという方法です。数字や名前の代わりに行数・列数と同じ長さのlogical型ベクトルを指定した場合,TRUEのところだけが抽出される仕組みになっています。まずは簡単なベクトルでその挙動を確認しましょう。
これを利用して,データフレームの最初の3行をlogical型を使って取り出してみます。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
1 1 2 4 3 4 4 2 3 3 4 4
2 2 2 4 5 2 5 5 4 4 3 4
3 3 5 4 5 4 4 4 5 4 2 5
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
1 3 3 3 4 4 3 4 2 2
2 1 1 6 4 3 3 3 3 5
3 2 4 4 4 5 4 5 4 2
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1 3 3 6 3 4 3 1 -99 16
2 5 4 2 4 3 3 2 -99 18
3 3 4 2 5 5 2 2 -99 17データフレームの長さと同じ長さのlogical型ベクトルは,比較演算子によって容易に生み出すことが出来ます。例えば「男性(genderが1の人)だけを見たい」としたら,まず抽出したい人のところがTRUEになっているベクトルを作ります。
[1] TRUE FALSE FALSE FALSE TRUE FALSE TRUE TRUE TRUE
[10] FALSE TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE
[19] FALSE FALSE TRUE FALSE TRUE FALSE TRUE FALSE FALSE
[28] FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE
[37] TRUE TRUE TRUE FALSE FALSE FALSE TRUE TRUE FALSE
[46] TRUE TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE
[55] TRUE TRUE FALSE TRUE FALSE TRUE TRUE TRUE FALSE
[64] FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE
[73] TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
[82] FALSE TRUE TRUE FALSE TRUE FALSE FALSE FALSE FALSE
[91] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE
[100] FALSE
[ reached 'max' / getOption("max.print") -- omitted 2700 entries ]あとは以下のように,行指定の場所にベクトルを与えるだけで抽出可能なわけです14。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
1 1 2 4 3 4 4 2 3 3 4 4
5 5 2 3 3 4 5 4 4 5 3 2
7 7 2 5 5 3 5 5 4 4 2 3
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
1 3 3 3 4 4 3 4 2 2
5 2 2 5 4 5 2 3 4 4
7 4 3 4 5 5 1 2 2 1
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1 3 3 6 3 4 3 1 -99 16
5 3 3 3 4 3 3 1 -99 17
7 1 5 2 5 6 1 1 -99 18
[ reached 'max' / getOption("max.print") -- omitted 916 rows ]もちろん1行にまとめて
としてもOKです。このあたりは見やすい方を選んでください。
他の比較演算子もまとめて紹介します。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
23 23 1 5 6 5 6 4 3 2 4 5
24 24 2 6 5 6 5 3 5 6 3 6
27 27 2 4 4 4 3 6 5 6 1 1
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
23 2 1 2 5 2 2 2 2 2
24 2 2 4 6 6 4 4 4 6
27 2 4 4 2 6 3 3 5 3
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
23 2 6 1 5 5 2 1 5 68
24 6 6 1 5 6 1 2 2 27
27 2 5 2 6 6 1 2 5 51
[ reached 'max' / getOption("max.print") -- omitted 1878 rows ] ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
6 6 6 6 5 6 5 6 6 6 1 3
11 11 4 4 5 6 5 4 3 5 3 2
23 23 1 5 6 5 6 4 3 2 4 5
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
6 2 1 6 5 6 3 5 2 2
11 1 3 2 5 4 3 3 4 2
23 2 1 2 5 2 2 2 2 2
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
6 3 4 3 5 6 1 2 3 21
11 3 5 3 5 6 3 1 1 21
23 2 6 1 5 5 2 1 5 68
[ reached 'max' / getOption("max.print") -- omitted 2022 rows ] ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
1 1 2 4 3 4 4 2 3 3 4 4
2 2 2 4 5 2 5 5 4 4 3 4
3 3 5 4 5 4 4 4 5 4 2 5
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
1 3 3 3 4 4 3 4 2 2
2 1 1 6 4 3 3 3 3 5
3 2 4 4 4 5 4 5 4 2
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1 3 3 6 3 4 3 1 -99 16
2 5 4 2 4 3 3 2 -99 18
3 3 4 2 5 5 2 2 -99 17
[ reached 'max' / getOption("max.print") -- omitted 2653 rows ]ちなみにノットイコールで使用した !記号は,多くの場面でTRUEとFALSEをひっくり返す役割を持っています。これは結構多用すると思うので覚えておきましょう(後でも出てきます)。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
6 6 6 6 5 6 5 6 6 6 1 3
11 11 4 4 5 6 5 4 3 5 3 2
38 38 1 4 4 2 3 6 5 6 3 4
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
6 2 1 6 5 6 3 5 2 2
11 1 3 2 5 4 3 3 4 2
38 3 4 3 3 5 5 6 5 5
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
6 3 4 3 5 6 1 2 3 21
11 3 5 3 5 6 3 1 1 21
38 4 5 5 4 5 2 1 3 21
[ reached 'max' / getOption("max.print") -- omitted 141 rows ]ただし実のところ,logical型ベクトルで行を指定すると,NA周りで面倒なことになります。なので特定の条件を満たす行を抽出する場合には,代わりにsubset()関数を使うようにしてください。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
23 23 1 5 6 5 6 4 3 2 4 5
27 27 2 4 4 4 3 6 5 6 1 1
33 33 1 5 6 5 4 1 5 6 4 6
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
23 2 1 2 5 2 2 2 2 2
27 2 4 4 2 6 3 3 5 3
33 6 6 2 1 1 1 2 1 3
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
23 2 6 1 5 5 2 1 5 68
27 2 5 2 6 6 1 2 5 51
33 6 6 6 5 6 1 1 5 23
[ reached 'max' / getOption("max.print") -- omitted 809 rows ]百聞は一見にしかずということで,早速やってみましょう。 今回使用しているデータでは,NAが-99という値で記録されているため,一旦「-99はNAのことだよ」と指定したうえで再度読み込みます。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
1 1 2 4 3 4 4 2 3 3 4 4
2 2 2 4 5 2 5 5 4 4 3 4
3 3 5 4 5 4 4 4 5 4 2 5
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
1 3 3 3 4 4 3 4 2 2
2 1 1 6 4 3 3 3 3 5
3 2 4 4 4 5 4 5 4 2
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education age
1 3 3 6 3 4 3 1 NA 16
2 5 4 2 4 3 3 2 NA 18
3 3 4 2 5 5 2 2 NA 17
[ reached 'max' / getOption("max.print") -- omitted 3 rows ]これで,データフレームの中にNAがある状態ができました。 ここで例えばdat_na[,"education"] == 1という比較演算が行われると,1の人はTRUE,それ以外の人はFALSEになりそうなものですが,実際にはNAの人はNAが返ってきます。
[1] NA NA NA NA NA FALSE NA FALSE TRUE
[10] NA TRUE NA NA NA TRUE NA NA NA
[19] NA NA NA NA FALSE FALSE TRUE FALSE FALSE
[28] NA FALSE FALSE NA FALSE FALSE NA FALSE FALSE
[37] FALSE FALSE NA FALSE FALSE FALSE TRUE FALSE FALSE
[46] FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
[55] FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE
[64] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[73] FALSE FALSE FALSE FALSE NA NA FALSE FALSE FALSE
[82] FALSE NA FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[91] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
[100] FALSE
[ reached 'max' / getOption("max.print") -- omitted 2700 entries ]これは,NAが「値がない」というよりは「いまは値が入っていないが,何かが入ってくる可能性は捨てていない」といった意味を持っているためです。 このため「現時点では値がないのでTRUEかFALSEか判断できない」という意味でNAを返してくるのです。
そして,以下のようにlogical型による行指定の際にNAが入っていると,そこには「全ての変数がNAになった行」が誕生します。酷い話です。
ID Q1_1 Q1_2 Q1_3 Q1_4 Q1_5 Q1_6 Q1_7 Q1_8 Q1_9 Q1_10
NA NA NA NA NA NA NA NA NA NA NA NA
NA.1 NA NA NA NA NA NA NA NA NA NA NA
NA.2 NA NA NA NA NA NA NA NA NA NA NA
Q1_11 Q1_12 Q1_13 Q1_14 Q1_15 Q1_16 Q1_17 Q1_18 Q1_19
NA NA <NA> NA NA NA NA NA NA NA
NA.1 NA <NA> NA NA NA NA NA NA NA
NA.2 NA <NA> NA NA NA NA NA NA NA
Q1_20 Q1_21 Q1_22 Q1_23 Q1_24 Q1_25 gender education
NA NA NA NA NA NA NA NA NA
NA.1 NA NA NA NA NA NA NA NA
NA.2 NA NA NA NA NA NA NA NA
age
NA NA
NA.1 NA
NA.2 NA
[ reached 'max' / getOption("max.print") -- omitted 444 rows ]具体的にこれが引き起こす問題としては,
NAが入っているために計算ができない(na.rm=TRUEとしたら良いですが)TRUE)の数」と合わないために計算や関数の挙動がおかしくなるなどが考えられます。
Rにデフォルトで入っているsummary()や,psych::describe(),Hmisc::describe()といった関数は,各変数の要約統計量を出してくれるものです。どれを使っても良い15のですが,ここではsummary()を使って変数の確認をしてみます。
psych::describe()など,関数名の左にパッケージ名と::を書いた表現は,どのパッケージの関数を使うかを明示するものです。例えばpsychとHmiscパッケージを両方ともlibrary()した状態でdescribe()関数を呼び出そうとすると,基本的には後に読み込んだほうのdescribe()関数が呼び出されるようになっているはずです(ちなみにどのパッケージの関数が呼び出されているかは,help()を使ったりするとわかります)。
だとすると,もし「Hmiscパッケージのdescribe()関数」を呼び出したい場合には,そもそもpsychパッケージをlibrary()しないようにしたり,両方library()するにしてもその順番を変える必要がありますが,これは明らかに面倒です。
このような場合に,Hmisc::describe()というように書けば,他のパッケージにあるdescribe()関数は気にせずに,確実に「Hmiscパッケージのdescribe()関数」を呼び出せるわけです。
また,この記法による関数の呼び出しは,パッケージをlibrary()していなくても使えます。そのため,あるパッケージの関数を一度しか使わない場合など「library()するほどではない」ときにも使えるので覚えておきましょう。上述したように,同名の関数の思わぬ衝突を避けられるかもしれません。
ID Q1_1 Q1_2
Min. : 1.0 Min. :-99.000 Min. :-99.000
1st Qu.: 700.8 1st Qu.: 1.000 1st Qu.: 4.000
Median :1400.5 Median : 2.000 Median : 5.000
Mean :1400.5 Mean : 1.834 Mean : 3.801
3rd Qu.:2100.2 3rd Qu.: 3.000 3rd Qu.: 6.000
Max. :2800.0 Max. : 6.000 Max. : 6.000
Q1_3 Q1_4 Q1_5
Min. :-99.000 Min. :-99.000 Min. :-99.00
1st Qu.: 4.000 1st Qu.: 4.000 1st Qu.: 4.00
Median : 5.000 Median : 5.000 Median : 5.00
Mean : 3.642 Mean : 3.996 Mean : 3.99
3rd Qu.: 6.000 3rd Qu.: 6.000 3rd Qu.: 5.00
Max. : 6.000 Max. : 6.000 Max. : 44.00
Q1_6 Q1_7 Q1_8
Min. :-99.000 Min. :-99.000 Min. :-99.000
1st Qu.: 4.000 1st Qu.: 4.000 1st Qu.: 4.000
Median : 5.000 Median : 5.000 Median : 5.000
Mean : 3.726 Mean : 3.484 Mean : 3.566
3rd Qu.: 5.000 3rd Qu.: 5.000 3rd Qu.: 5.000
Max. : 6.000 Max. : 6.000 Max. : 6.000 ちなみに,summary()系の関数は,変数の型に応じた要約統計量を返してくれます。
View()は, 図 1.16 のようにRstudioの中に操作可能なビューワーを表示してくれる関数です。値を書き換えることは出来ませんが,特定の列でソートしたり,フィルターをかけたりは出来ます。 生のRでも使えますが,日本語が文字化けしたり,本当にただ表示するだけなので使い勝手はあまり良くありません。

Rを開くたびに毎回元データを読み込んでコードを全部回すのは非効率&データサイズが大きいと時間がかかってしまうので,コードファイルは適当なところで区切り,処理後のデータを保存しておく(セーブポイントを作る)のがおすすめです。
(以下には,データを保存するための方法について最低限の解説をしていますが,Chapter 5-8で使用するデータは別のものです。そのため,以下の「Chapter 4までの処理が完了した状態」のファイルをダウンロードしておいてください。)
↓ファイルのダウンロードはこちらから
(あまり無いかもしれませんが)特にR以外のソフトウェアを使っている人とデータをやり取りする場合や,データの汎用性を高めたい場合には,CSV形式で保存しておくのが良いでしょう。
CSVに保存する場合は,write.csv()を使います。2つ目の引数が,保存するファイルの名前を指しています。他にもいくつかの引数がありますが,適宜設定しましょう。
| 引数名 | 説明 |
|---|---|
na |
NAのところにどういう文字を入れておくか。デフォルトはna="NA"ですが,他のソフトウェアで分析を続ける場合には変更する必要があるかもしれません。 |
row.names |
一番左の列に,行の名前16を入れるかを選びます。デフォルトでは行番号が入るのですが,これをまた読み込む際に行番号の列が1列目になり,全ての列が一つ右にずれることになります。そのため行の名前に特別な意味がなければ,FALSEにしておくことをおすすめします。 |
col.names |
先頭行に,列の名前を入れるかを選びます。普通は入れておけば良いですが,これもソフトウェアによっては「列名を入れるな。データだけにしろ。」というものもあるので,そのような際にはFALSEにしてあげてください。 |
CSVに保存する場合,変数の型(例えば前処理において型の変換を行った列など)の情報は記録されないため,読み込むたびに改めて行わなければいけない処理が発生します。 またCSVはデータフレームや行列などの2次元配列までしか保存できないため,データ以外の分析結果のオブジェクトを保存する際には,CSVは使えません。
このような場合,Rオブジェクトのまま保存するという手段があります。この授業でも,データの保存はこちらの方法で行うことにします。 特定のオブジェクトを保存する際には,saveRDS()という関数を使います(読み込みは次回の最初に)。
saveRDS()では一つのオブジェクトだけを保存しますが,場合によっては複数のオブジェクトをまとめて保存したい,何なら現時点での状態をそのまままるごと保存しておきたい,という場合もあるでしょう。 そのような場合はsave()やsave.image()関数が使えます。
ちなみにsave.image()でやっていることは,RやRstudioを閉じようとした際の質問で「保存」を選んだ時と同じです。この場合にはファイル名は指定できずに必ず(ドットの前に何もない)".Rdata"という名前になります。が,使う分には問題ありません。

ちなみにデキる大人はRの中でPythonを呼び出したり,その逆をしたりします。得意不得意があることをよく理解している人は,それぞれの言語に得意な作業を分担させたりするわけです。最近ではRからでもPythonからでもChatGPTを呼び出したりもできます。↩︎
「しぃらん」と読むらしいですね。↩︎
ただ最近ではRStudioの開発元がPositに改名されたように,RstudioでもRとPythonをだいぶ並行して扱えるようになっています。↩︎
実はPythonを始めとする多くのプログラミング言語では,+か*の演算が文字列に対しても適用可能です。これらの言語では,「数字同士だったら足し算(掛け算)をする」「どちらか一方でも文字列だったら文字列をくっつける」という処理が定義されていることが多いのです。したがって,Pythonでbox2 + 3とした場合には,"hello3"という値が出力されます。↩︎
Rでは,名前の直後に()がついている場合に,それを「関数」として認識します。この資料でも以降は,関数であることを表すときには関数名の後に空白のカッコをつけます。↩︎
というように,Rのvar()関数は不偏分散を計算する関数として用意されている一方,デフォルトでは標本分散を計算する関数が無いので,標本分散を計算したい場合はvar()/(n/(n-1))(nはデータの数)とかしてください。↩︎
combineの頭文字でcです。↩︎
あとは人に頼る能力も重要だと思います。↩︎
例えばですがこれより前にpsych <- "xxx"というコードを実行していた場合には,install.packages(psych)はinstall.packages("xxx")となるので,"xxx"が実在するパッケージ名であれば,(psychパッケージではなく)xxxパッケージをインストールします。↩︎
大学の学部でRの授業をすると,マジで何割かはこの質問が来ます。体感では一番のFAQです。↩︎
反対に,私の研究室にある書類をディレクトリ的に書くならば「兵庫県/神戸市/灘区/六甲台町/2/1/神戸大学/第4学舎/512/※※に関する書類」という感じになるわけです。郵便番号は「兵庫県/神戸市/灘区/六甲台町」というフォルダにつけられたニックネーム的なものということですね。↩︎
この場合character型とみなしても良さそうなものですが,全て実数なのでnumeric型とみなしたほうがしっくり来るだろう,と勝手に判断しているということです。↩︎
変数の性質を表すために「型」という概念があるように,データの構造を表すのもまた「型」なのです。↩︎
ちなみにイコールが一つだけ(=)の場合は<-と同じく代入の働きをします。よくあるミスなのでご注意ください。↩︎
psych::describe()を使うと「NAではない数」「標準偏差」「トリム平均」「尖度」「歪度」なども出してくれますが,第1・3四分位点は出してくれません(引数quantで追加は可能)。またHmisc::describe()ではデータの内容に合わせて度数分布や最大値・最小値トップ5を出してくれたり,いろいろな分位点を出してくれます。結局のところ,好きな関数を使えばOKです。↩︎
ID列とは別の話です。Rではデータフレームの中で,列とは別の扱いとして「行の名前」が指定できます。列名が「1行目」としては扱われないのと同じ感じです。↩︎