寈崘
寈崘偙偺僩僺僢僋偺忣曬偼丄僷僼僅乕儅儞僗偺奼挘庤朄傪巊梡偟偰偄偰丄嵟揔壔偟偰偄傞傾僾儕働乕僔儑儞宍幃偺夝愅偑嵪傫偱偄傞偙偲傪慜採偵愢柧偟偰偄傑偡丅
嵟揔側庤朄傪敾抐偡傞偨傔偵傾僾儕働乕僔儑儞偺僾儘僼傽僀儕儞僌傪峴偭偨屻丄僐儞僷僀儔乕偵傛偭偰峴傢傟偨嵟揔壔偍傛傃惂尷傪妋擣偟傑偡丅偦偟偰丄僐儞僷僀儔乕丒儗億乕僩傪巊梡偟偰丄師偵壗傪峴偆偐傪寛掕偟傑偡丅
儗億乕僩偺撪梕偵墳偠偰丄僐儞僷僀儔乕偑廳梫側傾乕僉僥僋僠儍乕忋偺婡擻傪妶梡偟偰嵟崅儗儀儖偺僷僼僅乕儅儞僗傪払惉偱偒傞傛偆偵丄僆僾僔儑儞丄僾儔僌儅傪慖戰偟丄昁梫側僐乕僪廋惓傪峴偄傑偡丅
僐儞僷僀儔乕丒儗億乕僩偼丄僐儞僷僀儔乕偵傛偭偰峴傢傟偨壖掕偵婎偯偄偰丄峴偆偙偲偑偱偒傞張棟偲偱偒側偄張棟傪帵偟傑偡丅僆僾僔儑儞偲僾儔僌儅傪怓乆偲帋偡偙偲偱丄僐儞僷僀儔乕偑峴偭偨壖掕傪棟夝偟丄傑偨丄怴偟偄嵟揔壔偺庤朄傗僥僋僯僢僋傪摫偒弌偡偙偲偑偱偒傑偡丅
偄偔偮偐偺廳梫側曽朄偱僐儞僷僀儔乕傪岠棪揑偵棙梡偱偒傑偡丅
揔愗側儗億乕僩傪撉傒丄僐儞僷僀儔乕偑峴偭偰偄傞偙偲偲僐儞僷僀儔乕偑僐乕僪偵娭偟偰峴偭偨壖掕傪棟夝偡傞丅
傾僾儕働乕僔儑儞偐傜嵟崅儗儀儖偺僷僼僅乕儅儞僗偑摼傜傟傞傛偆偵丄摿掕偺僆僾僔儑儞丄慻傒崬傒娭悢丄儔僀僽儔儕乕丄偍傛傃僾儔僌儅傪巊梡偡傞丅
椺偊偽丄扨惛搙抣偺暯曽崻傪愨偊偢寁嶼偡傞応崌丄扨惛搙僨乕僞宆梡偺揔愗側慻傒崬傒娭悢傪巊梡偡傞偲丄僷僼僅乕儅儞僗傪岦忋偱偒傑偡丅椺偊偽丄C 偱 sqrt() 偺戙傢傝偵 sqrtf() 傪巊梡偟傑偡丅
懠偺悇彠偡傞庤朄偼丄乽嵟揔壔庤朄偺揔梡乿傪嶲徠偟偰偔偩偝偄丅
儊儌儕乕丒僄僀儕傾僔儞僌偼丄IA-64 傾乕僉僥僋僠儍乕丒儀乕僗丒僔僗僥儉梡僀儞僥儖(R) 僐儞僷僀儔乕偺嵟揔壔偵嵟傕戝偒側塭嬁傪梌偊傞栤戣偱偡丅儊儌儕乕丒僄僀儕傾僔儞僌偼丄2 偮埲忋偺億僀儞僞乕偱巜掕偝傟偨儊儌儕乕偺応強偵彂偒崬傒傑偡丅偙偺傛偆側応崌丄僐儞僷僀儔乕偑嵟揔壔偟偡偓側偄傛偆偵拲堄偡傞昁梫偑偁傝傑偡丅僐儞僷僀儔乕偑嵟揔壔偟偡偓傞偲丄梊婜偟側偄摦嶌 (惓偟偔側偄寢壥丄堎忢廔椆丄偦偺懠) 傪堷偒婲偙偡偙偲偑偁傝傑偡丅
僐儞僷僀儔乕偼丄捠忢丄儌僕儏乕儖傗娭悢儀乕僗偱嵟揔壔傪峴偆偺偱丄娭悢傊搉偝傟傞僌儘乕僶儖曄悢傗儘乕僇儖曄悢偺巊梡傪慡懱偐傜尒偰敾抐偟偰偄傑偣傫丅偙偺偨傔丄僐儞僷僀儔乕偼丄捠忢丄娭悢偵搉偝傟偨偡傋偰偺億僀儞僞乕偑僄僀儕傾僗偝傟傞偲壖掕偟傑偡丅僐儞僷僀儔乕偼丄僄僀儕傾僗偝傟側偄偙偲偑傢偐偭偰偄傞億僀儞僞乕偵傕偙偺壖掕傪峴偄傑偡丅偙偺傛偆側摦嶌偼丄姰慡偵埨慡側儖乕僾偑僷僀僾儔僀儞壔傑偨偼儀僋僩儖壔偝傟偢丄僷僼僅乕儅儞僗偑岦忋偟側偄偙偲傪堄枴偟傑偡丅
億僀儞僞乕偑僄僀儕傾僗偝傟側偄偙偲傪僐儞僷僀儔乕偵抦傜偣傞曽朄偼偄偔偮偐偁傝傑偡丅
-fno-alias (Linux*) 傑偨偼 /Oa (Windows*) 偺傛偆側丄曪妵揑側僐儞僷僀儔乕丒僆僾僔儑儞傪巊梡偟傑偡丅偙傟傜偺僆僾僔儑儞偼丄偡傋偰偺儌僕儏乕儖偺億僀儞僞乕偑僄僀儕傾僗偝傟側偄偙偲傪僐儞僷僀儔乕偵抦傜偣傑偡丅僾儘僌儔儉偑惓妋偱偁傞偙偲偺愑擟偼丄奐敪幰偑晧偆偙偲偵側傝傑偡丅
-fno-fnalias (Linux) 傑偨偼
/Ow (Windows) 偺傛偆側丄偁傑傝曪妵揑偱偼側偄僐儞僷僀儔乕丒僆僾僔儑儞傪巊梡偟傑偡丅偙傟傜偺僆僾僔儑儞偼丄娭悢偺堷悢偱搉偝傟偨億僀儞僞乕偑僄僀儕傾僗偝傟側偄偙偲傪僐儞僷僀儔乕偵抦傜偣傑偡丅
娭悢偺堷悢偼丄僐儞僷僀儔乕偵柧妋偵偱偒傞愽嵼揑側僄僀儕傾僔儞僌偺堦斒揑側椺偱偡丅娭悢偵搉偝傟傞堷悢偼僄僀儕傾僗偝傟側偄偙偲偑傢偐偭偰偄傑偡偑丄僐儞僷僀儔乕偼僄僀儕傾僗偝傟傞偲壖掕偟傑偡丅偟偐偟丄偙傟傜偺僆僾僔儑儞偼丄娭悢偺堷悢偑僄僀儕傾僗偝傟側偄偲壖掕偟偰傕埨慡偱偁傞偙偲傪僐儞僷僀儔乕偵抦傜偣傑偡丅偙偺僆僾僔儑儞偼丄-fno-nalias (Linux) 傑偨偼 /Ow
(Windows) 僆僾僔儑儞傪巊梡偟偰僐儞僷僀儖偝傟偨儌僕儏乕儖偺偡傋偰偺娭悢偵塭嬁偡傞揰偵拲堄偟偰偔偩偝偄丅
ivdep 僾儔僌儅傪巊梡偟傑偡丅傑偨偼丄娭悢偺巜掕偝傟偨儖乕僾偵揔梡偡傞僾儔僌儅傪巊梡偟傑偡丅偡傋偰偺娭悢傪巜掕偡傞傛傝傕惓妋偱偡丅僾儔僌儅偼丄巜掕偝傟偨儖乕僾偵偮偄偰偼丄儀僋僩儖偺埶懚惈偑側偄偲抐掕偟傑偡丅杮幙揑偵偼丄億僀儞僞乕偑巜掕偝傟偨儖乕僾偱僄僀儕傾僔儞僌偟偰偄側偄偲尵偆偺偲摨偠偙偲偱偡丅
restrict 僉乕儚乕僪傪巊梡偟傑偡丅億僀儞僞乕傪柧妋偵偡傞傛傝惓妋側曽朄偼丄restrict 僉乕儚乕僪偱偡丅restrict 僉乕儚乕僪偼丄僄僀儕傾僗偝傟偰偄側偄屄乆偺億僀儞僞乕傪幆暿偡傞偨傔偵巊梡偝傟傑偡丅restrict 僉乕儚乕僪偼丄巜掕偝傟偨儊儌儕乕偺応強偑懠偺億僀儞僞乕偵傛偭偰彂偒崬傑傟側偄傛偆偵僐儞僷僀儔乕偵抦傜偣傑偡丅
師偺椺偼丄restrict 僉乕儚乕僪傪巊梡偟偰丄z 偱巜偝傟偨儊儌儕乕傾僪儗僗偑懠偺億僀儞僞乕偵傛偭偰彂偒崬傑傟側偄偙偲傪僐儞僷僀儔乕偵抦傜偣傑偡丅偙偺怴偟偄忣曬偵傛傝丄僐儞僷僀儔乕偼儖乕僾傪師偺傛偆偵儀僋僩儖壔傑偨偼僜僼僩僂僃傾偺僷僀僾儔僀儞壔偱偒傑偡丅
椺 |
|---|
|
// One-dimension array. void restrict1(int *x, int *y, int * restrict z) { int A = 42; int i; double temp; for(i=0;i<100;i++) { z[i] = A * x[i] + y[i]; } } // Two-dimension array. void restrict2(int a[][100], int b[restrict][100]) { /* ... */ } |
寈崘忋婰偺椺偺傛偆偵 restrict 僉乕儚乕僪傪巊梡偡傞偵偼丄僐儞僷僀儖峴偱 -restrict (Linux) 傑偨偼 /Qrestrict (Windows) 僆僾僔儑儞傪巊梡偡傞昁梫偑偁傝傑偡丅
僷僼僅乕儅儞僗偵戝偒側塭嬁傪梌偊傞暿偺栤戣偼丄旕儐僯僢僩僗僩儔僀僪曽幃偵偍偗傞儊儌儕乕傾僋僙僗偱偡丅偙傟偼丄撪晹儖乕僾偑楢懕揑偵僀儞僋儕儊儞僩偟丄椬愙偟偰偄側偄応強偐傜儊儌儕乕偵傾僋僙僗偟偰偄傞偙偲傪堄枴偟傑偡丅椺偊偽丄師偺傛偆側峴楍忔嶼僐乕僪傪峫偊偰傒傑偡丅
椺 |
|---|
|
// Non-Unit Stride access problem with b[k][j] void non_unit_stride(int **a, int **b, int **c) { int A = 42; for(int i=0; i<A; i++) for(int j=0; j<A; j++) for(int k=0; k<A; k++) c[i][j] = c[i][j] + a[i][k] * b[k][j]; } |
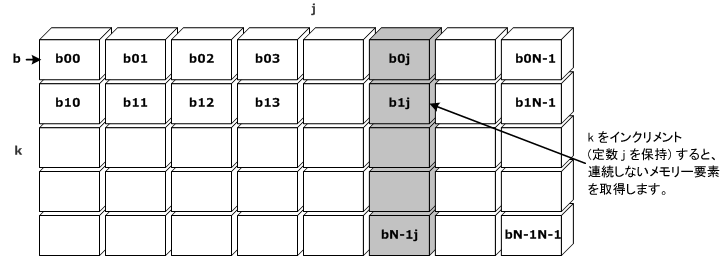
攝楍偵娭楢偟偨嵟撪儖乕僾偑僀儞僋儕儊儞僩偝傟傞偲偒偵丄c[i][j] 偍傛傃 a[i][k] 偺椉曽偑楢懕偡傞儊儌儕乕偺応強偵傾僋僙僗偡傞揰偵拲堄偟偰偔偩偝偄丅偟偐偟丄攝楍 b 偼丄僀儞僨僢僋僗 k 偍傛傃 j 偺儖乕僾偱儊儌儕乕丒儐僯僢僩丒僗僩儔僀僪偵傾僋僙僗偟傑偣傫丅儖乕僾偑 b[k=0][j=0] 傪撉傫偩屻丄k 儖乕僾偑 1 偐傜 b[k=1][j=0] 偵僀儞僋儕儊儞僩偝傟傑偡丅
偙偺栤戣偵懳張偡傞偵偼丄儖乕僾曄姺 (儖乕僾岎姺偲傕屇偽傟傑偡) 傪峴偄傑偡丅僐儞僷僀儔乕偱儖乕僾岎姺傪帺摦揑偵峴偭偨偲偟偰傕丄昁偢偟傕偡傋偰偺婡夛傪擣幆偡傞偲偼尷傝傑偣傫丅
忋婰偺椺偺儊儌儕乕丒傾僋僙僗丒僷僞乕儞偼丄師偺恾偺傛偆偵側傝傑偡丅
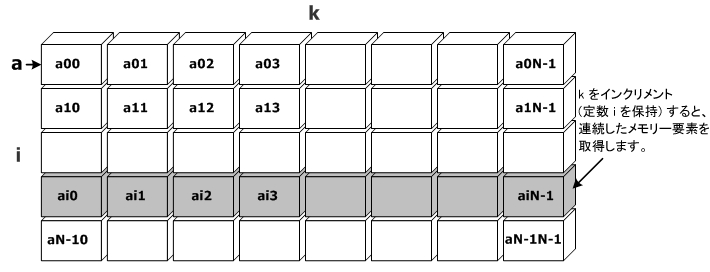
忋婰偺椺偵丄儖乕僾岎姺傪峴偆偨傔偵師偺傛偆側曄峏傪壛偊偨偲偟傑偡丅
椺 |
|---|
|
// After loop interchange of k and j loops. void unit_stride(int **a, int **b, int **c) { int A = 42; for(int i=0; i<A; i++) for(int k=0; k<A; k++) for(int j=0; j<A; j++) c[i][j] = c[i][j] + a[i][k] * b[k][j]; } |
儖乕僾岎姺偺屻丄儊儌儕乕丒傾僋僙僗丒僷僞乕儞偼師偺恾偺傛偆偵側傝傑偡丅