 注
注インテルの OpenMP* ランタイム・ライブラリーには、OpenMP スレッドを物理プロセシング・ユニットにバインドする機能があります。このインターフェイスは、KMP_AFFINITY 環境変数により制御されます。システムのトポロジー、アプリケーション、オペレーティング・システムによってスレッド・アフィニティーはアプリケーションの速度に大きく影響します。
注Linux のみ。クラスター OpenMP の場合、この環境変数はランタイムシステムによって作成された各プロセスに個別に適用され、グローバルスレッド ID は各プロセスとすべてのプロセスで連続した数字が割り当てられます。個々のシステムのトポロジーマップとメッセージリストは各プロセスに対して作成されます。
KMP_AFFINITY 環境変数には、次の一般的な構文が使用されます。
構文 |
|---|
|
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>] |
次の表は、サポートされる引数のリストです。
| 引数 |
デフォルト |
説明 |
|---|---|---|
|
modifier |
noverbose respect granularity=core |
オプションです。キーワードと指定子から構成されます。
|
|
type |
none |
必須です。使用するスレッド・アフィニティーを示します。
logical と physical は推奨されていないタイプですが、下位互換性のためにサポートされています。 |
|
permute |
0 |
オプションです。正の整数値です。 |
|
offset |
0 |
オプションです。正の整数値です。 |
"type" は、唯一必須の引数です。
OpenMP スレッドは特定のスレッド・コンテキストにバインドされません。ただし、オペレーティング・システムでアフィニティーがサポートされる場合は、コンパイラーは OpenMP スレッド・アフィニティー・インターフェイスを使用してシステムのトポロジーを特定します。
KMP_AFFINITY=verbose,none を指定して、システムのトポロジーマップをリストします。
compact を指定すると、フリー・スレッド・コンテキストの OpenMP スレッド <n>+1 は、OpenMP スレッド <n> がバインドされたスレッドコンテキストにできる限り近いスレッド・コンテキストにバインドされます。例えば、トポロジーマップで、ルートにより近いノードほど、スレッドをソートしたときに上位になります。
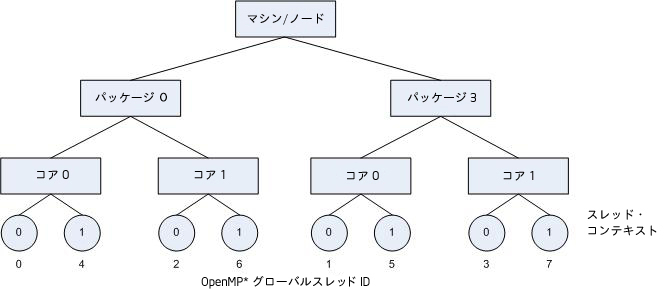
次の図は、2 台のプロセッサーを搭載しているシステムを示しています。それぞれのプロセッサーには 2 つのコアがあります。各コアはハイパースレッディング・テクノロジー (HT テクノロジー) 対応です。
また、次の図は、KMP_AFFINITY=granularity=fine,compact を指定したときに、OpenMP スレッドがハードウェア・スレッド・コンテキストにバインドされる様子も示しています。

IA-32 アーキテクチャーおよびインテル(R) 64 アーキテクチャーで、パッケージに APIC (Advanced Programmable Interrupt Controller) が含まれている場合、コンパイラーは cpuid 命令を使用してパッケージ ID、コア ID、スレッド・コンテキスト ID を取得します。通常の状態では、マシン上の各スレッド・コンテキストには起動時に固有の APIC ID が割り当てられます。パッケージ上のコア ID とコア上のスレッド・コンテキスト ID には連続した番号が使用されますが、上の図のようにパッケージ ID は連続した番号ではないのが一般的です。
IA-64 アーキテクチャー上の Linux の場合は、コンパイラーは /proc/cpuinfo を使用します。パッケージ ID、コア ID、スレッド・コンテキスト ID は、/proc/cpuinfo の "physical id" フィールド、"core id" フィールド、"thread id" フィールドから取得されます。コア ID とスレッド・コンテキスト ID のデフォルトは 0 ですが、マシントポロジーを特定するため、"physical id" フィールドが必要です。
アフィニティーがオペレーティング・システムでサポートされているが、コンパイラーがいずれの方法を使用してもシステムのトポロジーを特定できない場合は、警告メッセージが出力され、トポロジーはフラットとみなされます。例えば、オペレーティング・システムのプロセッサー N はパッケージ N にマップされているとされ、1 つのコアに 1 つのスレッド・コンテキスト、1 つのパッケージに 1 つのコアがあると想定されます。(Windows を実行する IA-64 アーキテクチャーをベースとしたプロセッサーの場合は常にこのように仮定されます。)
マシントポロジーを特定するのに、どのような方法が使用されたとしても、システムのすべてのコアにおいて 1 つのコアに 1 つのスレッド・コンテキストしかない場合は、トポロジーマップにはスレッド・コンテキスト・レベルは表示されません。また、システムのすべてのパッケージにおいて、1 つのパッケージに 1 つのコアしかない場合は、コアレベルはトポロジーマップには表示されません。
パッケージレベルは、システムに 1 つのパッケージしかない場合でも常にトポロジーマップに表示されます。
scatter を指定すると、システム全体にわたってスレッドが均等に分配されます。scatter は、compact の逆です。そのため、システムのトポロジーマップをソートするとノードリーフは最上位になります。上の図と同じシステムで scatter を指定すると、次の図のように OpenMP スレッドがスレッド・コンテキストに割り当てられます。
次の図は、KMP_AFFINITY=granularity=fine,scatter を指定した場合を示しています。
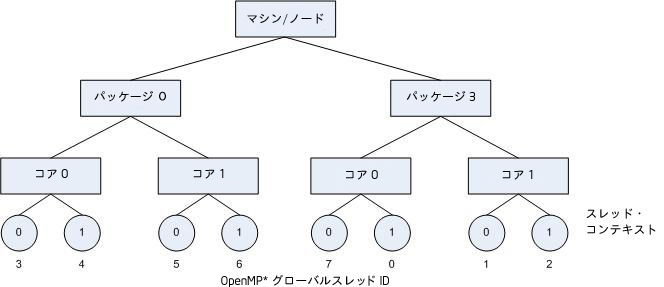
compact と scatter の両方とも permute と offset が指定できます。ただし、1 つの整数だけを指定した場合は、コンパイラーは値を permute 指定子として解釈します。permute と offset の両方ともデフォルトは 0 です。
permute 指定子はシステムのトポロジーマップをソートしたときに最上位にするレベルを制御します。permute の値により、指定された番号の最上位レベルは最下位にマッピングされ、順位が入れ替わります。ツリーのルートノードは、ソート操作では個別のレベルとはみなされません。
offset 指定子は、スレッド割り当ての開始地点を示します。
次の図は、KMP_AFFINITY=granularity=fine,compact,0,3 を指定した結果を示しています。
通常、スレッドは、同じコアにある別のアクティブなスレッドとの間にリソースの競合がない場合に実行速度が速くなります。そのため、別のコアを使用せずに複数のスレッドを同じコアにバインドするのは避けたほうが良いでしょう。次の図は、KMP_AFFINITY=granularity=fine,compact,1,0 を設定してこの方法を示したものです。
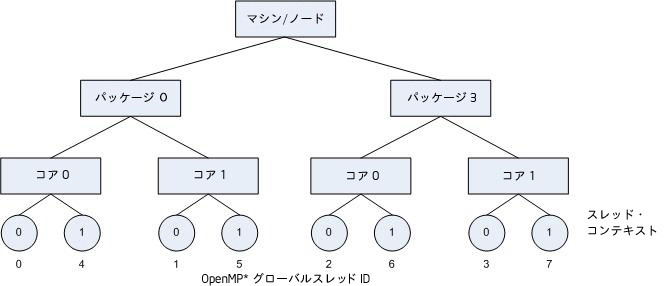
OpenMP スレッド <n>+1 は、別のコアの OpenMP スレッド <n> にできるだけ近いスレッド・コンテキストにバインドされます。いったん、それぞれのコアに 1 つの OpenMP スレッドが割り当てられたら、後続の OpenMP スレッドは利用可能なコアに同じ順番で、バインドされていないスレッドコンテキストに割り当てられます。
logical と physical は推奨されていないタイプですが、両方とも下位互換性のためにサポートされています。代わりに compact または scatter を使用してください。logical および physical では、整数値が 1 つしかない場合は、permute 指定子ではなく、offset 指定子と解釈されます。これに対し、compact タイプと scatter タイプでは、整数値が 1 つのみの場合は permute 指定子と解釈されます。
OpenMP スレッドを連続した論理プロセッサー (ハードウェア・スレッド・コンテキストとも呼ぶ) に割り当てます。このタイプは、permute 指定子が使えないことを除いては、compact と同等です。
OpenMP スレッドを連続した物理プロセッサー (例: コア) に割り当てます。コアごとに 1 つのスレッド・コンテキストしかないシステムの場合、logical と同じです。コアごとに複数のスレッド・コンテキストがあるシステムの場合は、physical は、permute 指定子が 1 に指定された compact と同じです。これは、コンパイラーがマップをソートしたときにマシンのトポロジーマップの最も内側のレベルを最も外側 (おそらくスレッド・コンテキスト・レベル) に入れ替えることを意味します。このタイプでは permute 指定子はサポートされません。
タイプの前に付ける修飾子はオプションです。修飾子を指定しない場合は、noverbose、respect、granularity=core が自動で使用されます。
修飾子は、左から右の順に解釈され、互いに無効にすることができます。
詳細なメッセージは出力しません。
サポートされるアフィニティーに関するメッセージを出力します。メッセージには、パッケージ数、各パッケージにあるコア数、各コアにあるスレッド・コンテキスト数、物理スレッド・コンテキストにバインドされた OpenMP スレッドについての情報が含まれます。
物理スレッド・コンテキストにバインドされた OpenMP スレッドについての情報は、間接的に、ハードウェア・スレッド・コンテキストからオペレーティング・スレッド ID 間のマッピングの形式で示されます。各 OpenMP スレッドのアフィニティー・マスクは、オペレーティング・システムのプロセッサー ID セットとして出力されます。
例えば、HT テクノロジーを無効にした 2 台のプロセッサーを搭載したデュアルコア・システムで KMP_AFFINITY=verbose,scatter を指定すると、次のようなメッセージが出力されます。
Verbose, scatter を指定した場合のメッセージ |
|---|
|
... KMP_AFFINITY: Affinity 可、グローバル cpuid 情報使用 KMP_AFFINITY: 初期 OS proc セット respected: {0,1,2,3} KMP_AFFINITY: 4 利用可能な OS proc 数 KMP_AFFINITY: 2 pkg 数 x 2 コア数/pkg x 1 スレッド数/コア (4 合計コア数) KMP_AFFINITY: OS proc から物理スレッドマップ ([] => マップにないレベル): KMP_AFFINITY: OS proc 0 をパッケージ 0 [コア 0] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 2 をパッケージ 0 [コア 1] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 1 をパッケージ 3 [コア 0] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 3 をパッケージ 3 [コア 1] [スレッド 0] にマップします。 KMP_AFFINITY: 内部スレッド 0 が OS proc セット {0} にバウンドします。 KMP_AFFINITY: 内部スレッド 2 が OS proc セット {2} にバウンドします。 KMP_AFFINITY: 内部スレッド 3 が OS proc セット {3} にバウンドします。 KMP_AFFINITY: 内部スレッド 1 が OS proc セット {1} にバウンドします。 |
verbose 修飾子を指定するといくつかの標準的、一般的なメッセージが生成されます。次の表は、メッセージの説明です。
メッセージ |
説明 |
|---|---|
|
"affinity capable" |
すべてのコンポーネント (コンパイラー、オペレーティング・システム、ハードウェア) でスレッドのバインドが可能なようにアフィニティーがサポートされていることを示します。 |
|
"using global cpuid info" |
スレッドを各オペレーティング・システムのプロセッサーにバインドし、cpuid 命令の出力をデコードすることにより、マシントポロジーが特定されたことを示します。 |
|
"using local cpuid info" |
コンパイラーは初期スレッドのみから発行される cpuid 命令の出力をデコードし、マシントポロジーでオペレーティング・システムのプロセッサー数が使用されていると想定していることを示します。 |
|
"using /proc/cpuinfo" |
Linux のみ。cpuinfo がシステムトポロジーを特定するのに使用されることを示します。 |
|
"flat" |
オペレーティング・システムのプロセッサー ID は、物理パッケージ ID と同じとみなされています。システムトポロジーを特定するこの方法は、その他の方法がどれも使用できず、また実際のマシントポロジーを正しく検出しない可能性がある場合に使用されます。 |
|
"uniform topology of" |
システムトポロジーのマップは、どの階層においてもリーフがそろった完全なツリーです。 |
次に、オペレーティング・システムのプロセッサーからパッケージ ID、コア ID、スレッド・コンテキスト ID へのマッピングが出力されます。OpenMP スレッドのスレッド・コンテキスト ID へのバインドは、アフィニティーのタイプが none でない限り、次に出力されます。スレッドレベルは、角括弧の中に示されます (上のリストを参照)。これは、マシントポロジーのマップにスレッド・コンテキスト・レベルを表現するものがないことを示します。
OpenMP スレッドを特定のパッケージやコアにバインドすると、HT テクノロジーが有効なインテル(R) プロセッサーを搭載したシステムでパフォーマンス・ゲインを期待できます。しかし、一般的に各 OpenMP スレッドを特定のコアにある特定のスレッド・コンテキストにバインドしても効果は期待できません。粒度は、トポロジーマップ内で OpenMP スレッドのフロートが許可される最下位レベルを示します。
この修飾子は、次の指定子をサポートします。
指定子 |
説明 |
|---|---|
|
core |
デフォルト。サポートされる最も荒い粒度レベルです。すべての OpenMP スレッドが異なるスレッド・コンテキスト間でフロートするために、コアにバインドできます。 |
|
fine または thread |
最も細かい粒度レベルです。各 OpenMP スレッドが 1 つのスレッド・コンテキストにバインドされます。この 2 つの指定子は、機能的に同じです。 |
2 台のプロセッサーを搭載したデュアルコア・システムで、HT テクノロジーが有効な場合に、KMP_AFFINITY=verbose,granularity=core,compact を指定すると、次のようなメッセージが出力されます。
Verbose, granularity=core,compact を指定した場合のメッセージ |
|---|
|
KMP_AFFINITY: Affinity 可、グローバル cpuid 情報使用 KMP_AFFINITY: 初期 OS proc セット respected: {0,1,2,3,4,5,6,7} KMP_AFFINITY: 8 利用可能な OS proc 数 KMP_AFFINITY: 2 pkg 数 x 2 コア数/pkg x 2 スレッド数/コア (4 合計コア数) KMP_AFFINITY: OS proc から物理スレッドマップ ([] => マップにないレベル): KMP_AFFINITY: OS proc 0 をパッケージ 0 [コア 0] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 4 をパッケージ 0 [コア 0] [スレッド 1] にマップします。 KMP_AFFINITY: OS proc 2 をパッケージ 0 [コア 1] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 6 をパッケージ 0 [コア 1] [スレッド 1] にマップします。 KMP_AFFINITY: OS proc 1 をパッケージ 3 [コア 0] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 5 をパッケージ 3 [コア 0] [スレッド 1] にマップします。 KMP_AFFINITY: OS proc 3 をパッケージ 3 [コア 1] [スレッド 0] にマップします。 KMP_AFFINITY: OS proc 7 をパッケージ 3 [コア 1] [スレッド 1] にマップします。 KMP_AFFINITY: 内部スレッド 0 が OS proc セット {0,4} にバウンドします。 KMP_AFFINITY: 内部スレッド 1 が OS proc セット {0,4} にバウンドします。 KMP_AFFINITY: 内部スレッド 2 が OS proc セット {2,6} にバウンドします。 KMP_AFFINITY: 内部スレッド 3 が OS proc セット {2,6} にバウンドします。 KMP_AFFINITY: 内部スレッド 4 が OS proc セット {1,5} にバウンドします。 KMP_AFFINITY: 内部スレッド 5 が OS proc セット {1,5} にバウンドします。 KMP_AFFINITY: 内部スレッド 6 が OS proc セット {3,7} にバウンドします。 KMP_AFFINITY: 内部スレッド 7 が OS proc セット {3,7} にバウンドします。 |
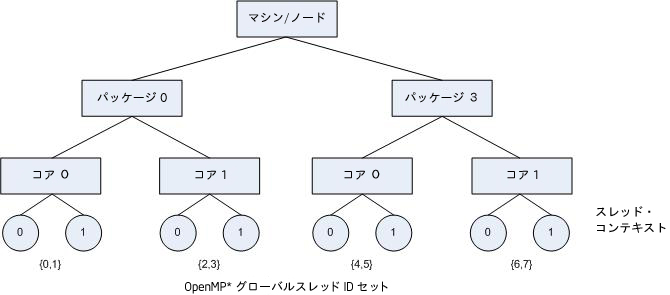
各 OpenMP スレッドのアフィニティー・マスクは、OpenMP スレッドがバインドされたオペレーティング・システムのプロセッサー・セットとしてリストされます (上を参照)。
次の図は、OpenMP スレッドがバインドされた上のリストのマシン・トポロジーを示しています。
これに対し、KMP_AFFINITY=verbose,granularity=fine,compact または KMP_AFFINITY=verbose,granularity=thread,compact を指定すると、各 OpenMP スレッドが 1 つのハードウェア・スレッド・コンテキストにバインドされます。
Linux と Windows では動作が異なります。
Windows: プロセスの元のアフィニティー・マスクが順守されます。
Linux: OpenMP ランタイム・ライブラリーを初期化するスレッドのアフィニティー・マスクが順守されます。
前の例と同じ、HT テクノロジーが有効なシステムで、KMP_AFFINITY=verbose,compact を指定して、最初のアフィニティー・マスク {4,5,6,7} (各コアでスレッド・コンテキストは 1) を起動すると、コンパイラーでは、HT テクノロジーが無効の 2 台のプロセッサーを搭載したデュアルコア・システムであると判断されます。
Verbose,compact を指定した場合のメッセージ |
|---|
|
KMP_AFFINITY: Affinity 可、グローバル cpuid 情報使用 KMP_AFFINITY: 初期 OS proc セット respected: {4,5,6,7} KMP_AFFINITY: 4 利用可能な OS proc 数 KMP_AFFINITY: 2 pkg 数 x 2 コア数/pkg x 1 スレッド数/コア (4 合計コア数) KMP_AFFINITY: OS proc から物理スレッドマップ ([] => マップにないレベル): KMP_AFFINITY: OS proc 4 をパッケージ 0 [コア 0] [スレッド 1] にマップします。 KMP_AFFINITY: OS proc 6 をパッケージ 0 [コア 1] [スレッド 1] にマップします。 KMP_AFFINITY: OS proc 5 をパッケージ 3 [コア 0] [スレッド 1] にマップします。 KMP_AFFINITY: OS proc 7 をパッケージ 3 [コア 1] [スレッド 1] にマップします。 KMP_AFFINITY: 内部スレッド 4 が OS proc セット {0} にバウンドします。 KMP_AFFINITY: 内部スレッド 1 が OS proc セット {6} にバウンドします。 KMP_AFFINITY: 内部スレッド 2 が OS proc セット {5} にバウンドします。 KMP_AFFINITY: 内部スレッド 3 が OS proc セット {7} にバウンドします。 KMP_AFFINITY: 内部スレッド 4 が OS proc セット {4} にバウンドします。 KMP_AFFINITY: 内部スレッド 5 が OS proc セット {6} にバウンドします。 KMP_AFFINITY: 内部スレッド 6 が OS proc セット {5} にバウンドします。 KMP_AFFINITY: 内部スレッド 7 が OS proc セット {7} にバウンドします。 |
システムには、8 個のスレッド・コンテキストがあるため、デフォルトではコンパイラーにより OpenMP parallel 構造で 8 個のスレッドが作成されています。
"thread 1" の角括弧はスレッド・コンテキストのレベルが無視され、トポロジーマップには示されていないことを意味します。次の図は、対応するシステムのトポロジーマップです。
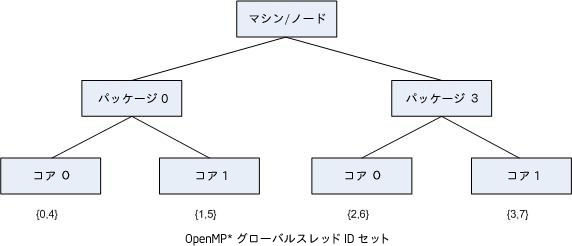
ローカルの cpuid 情報を使用してマシントポロジーを特定する場合、ハイパースレッディング・テクノロジーをサポートしていないマシンとサポートしているけれども無効になっているマシンとの区別がつきません。そのため、そのレベルの要素 (ノード) に兄弟がいない場合は、コンパイラーはそのレベルをマップに含めません (ただし、パッケージレベルは常に含まれます)。前述したように、パッケージレベルは、システムに 1 つのパッケージしかない場合でも、常にトポロジーマップに表示されます。
プロセスのアフィニティー・マスクは順守されません。OpenMP スレッドはすべてのオペレーティング・システムのプロセッサーにバインドされます。
physical と logical のみがアフィニティー・タイプとしてサポートされていた以前のバージョンの OpenMP ランタイム・ライブラリーでは、norespect がデフォルトで、修飾子としては認識されませんでした。
compact と scatter がアフィニティー・タイプに追加されてから、デフォルトは respect に変更されました。そのため、アプリケーションが不完全な初期のスレッド・アフィニティー・マスクを指定した状態では、logical と physical のスレッドのバインドは、新しいコンパイラー・バージョンで変更されることがあります。